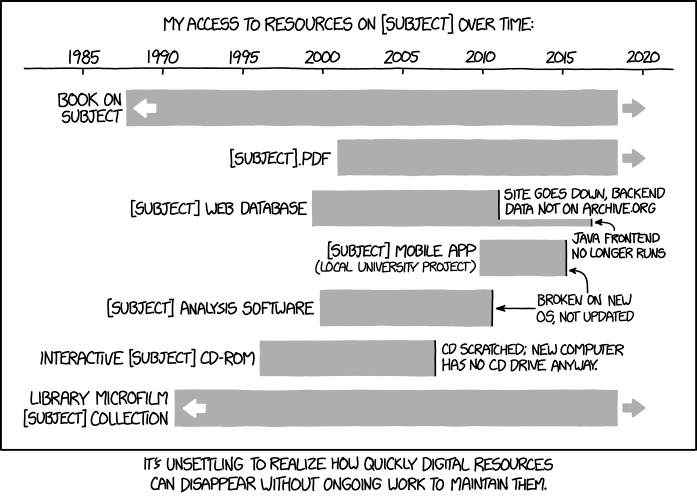
I'm frequently working on prototype hardware whose design bears only a superficial resemblance to what we are eventually going to ship. Sometimes there is a couple generations of prototypes in very different form factors, with the final version arriving not much before our ship date. Prototypes give the software team a head start (the header, the better) while the hardware team (with a little help from guys like me) work out the bugs in the hardware design. I may find myself rolling an engineering model running on batteries around in a parking lot to test that the cellular modem transitions seamlessly between cell towers. Or crawling around in a twin-engine executive business jet trying to figure out why the satellite communications unit isn't coming up. Or sitting on the floor in a drafty and noisy and sometimes dark server or telecom room between equipment racks, tangled in a maze of cables, with a laptop in my lap.
I
love doing this kind of work. But it does require a fair amount of flexibility and no small amount of improvisation on my part. Here - in no particular order - are some of the tools I've found useful over the past few years. Maybe you will too.
Cheater Safety Glasses
Disposable Ear Plugs

The LASIK surgery I got eons ago was a miracle; I still have 20/20 distance vision. But the older I get, the worse my close up vision becomes. So besides protecting my eyes, these safety glasses, that have reading glasses molded into them at the bottom of each lens, let me see what the display on that SATCOM box in the equipment bay is actually telling me. I keep a pair of these in just about every tool kit I have, in my daily briefcase, and in the garage at home. I buy 150s (1.5 diopter) currently, but alas soon to be 175s, at my local hardware store.
My hearing, which has never been very good (a youth spent target shooting, riding motorcycles, and working in white-noisy computer and equipment rooms), hasn't gotten any better. I try to protect what little I have with disposable foam ear plugs. I have several different kinds laying around, but these
E.A.R. brand Taperfit with the lanyard work best for me for day to day work. I use them in the lab, in the equipment and server rooms, and on site like when the pilot fires up the auxiliary power unit. Sometimes I use them at the coffee shop. You can buy these at your local hardware store too, but I order the big industrial sized box of individually wrapped ones from Amazon and hand them out (some might say forcibly) to co-workers.
Roll Your Own Custom Outlet Strip

I buy these little
outlet expanders and
grounded switches and when circumstances require I fabricate my own outlet strip on the spot. The outlet expanders play well with power bricks, and have a little light to indicate that they are electrified. You can place the switches wherever you need to control power to an individual device or set of devices. Add a heavy duty extension cord, and you have a really useful and flexible piece of electrical power distribution kit.
Folding Stool

My knees are getting too old to squat on the floor as I peer at some piece of gear. So I buy these
folding stools. Sometimes I sit on them, sometimes I sit on the floor and use them as a laptop stand. They are sturdy, can handle my manly weight, are easy to schlep around, and when folded don't take up much room. I order them from Amazon, but I've seen something similar at my local hardware store.
Aluminum Project Clipboard


When I head to the hardware store to buy something to solve some problem in the lab, I don't want to find out I should have brought a tape measure. Or reading glasses. Or writing material. Or a compass (seriously). I find these aluminum project clipboards, beloved by state highway patrol officers everywhere, really useful. They are pretty indestructible, and hold a bunch of useful stuff inside. Also useful in the field, for all the same reasons. I got this one at my local hardware store.
Velcro Cable Ties

I don't know how I lived without these. When I get a new cable - ethernet, USB, video, electrical, doesn't matter - the first thing I do now is toss the useless wire cable tie and replace it with one of these
velcro cable ties. They come on continuous perforated spools of 25, so you just unwrap one and tear it off. They have a loop hole on one end so you can lasso them to one end of the cable, or connect several together when you need a longer cable tie. They can be easily trimmed with scissors to make them shorter and easier to deal with. My only complaint is they only come in black or gray; I'd like something like safety orange or high-visibility yellow or even shocking pink. I buy them at my local office supply store.
Zip-lock Bags

Embedded development means having a lot of small related parts and other crap you have to keep track of. I like these Hefty-brand bags with the sliding zip-lock for that. They come in lots of sizes; I have at least one box of each. They have a label area that takes well to writing on with a Sharpie. They are cheap and sturdy. I keep everything from connectors to a Raspberry Pi with its power supply in them. I buy these at my local grocery.
Quirky Cordies Cable Organizer

I have a dozen of these
Quirky Cordies cable organizers laying around or permanently assigned to specific tasks. You place cables in between the upright loopy fingers. The Cordies are weighted in the base so they tend not to get pulled off lab benches or window sills (antennas, you know) by the weight of the cables they are holding. They come in a variety of colors (although again not safety orange or high-visibility yellow). I order these off Amazon. I can see
seven of them just as I sit here writing this at my lab bench in my home office.
Improvised Ground
Anti-Static Strap

Ideally when you use an anti-static strap - you
are using an anti-static strap, aren't you? - you want to ground yourself to the chassis or grounding point of whatever you are working on. Easy in the lab, sometimes not to simple in the field. Although it's not the perfect solution, I came up with these improvised grounds by buying
three-prong plugs, and
grounding wires (package of two), at my local hardware store. Five minutes spent putting them together makes for an improvised ground in any grounded outlet I plug it into. You do have to be aware of the possibility of ground loops if the stuff you are working on isn't plugged into the same electrical circuit, so some caution is called for.
Although any anti-static strap is better than no anti-static strap, I like
these with the Twist-O-Flex bands. I buy them off Amazon. The alligator clip pulls off to reveal a male connector compatible with the female plugs on the anti-static mats I like to use.
Thermal Label Maker

Folks that work with me will tell you I am an obsessive-compulsive labeler. That's why when the quality process inspector comes by to do an audit, it's
my lab bench they take them to. I also add my email address and phone number to most of the equipment my company owns in addition to an official property tag. Lots of folks make these thermal label makers, all of which use proprietary cassettes containing a spool of thermal label tape, and which typically come in a variety of foreground and background colors. I think Brother may have discontinued this particular model, which I like because it is capable of printing two lines of text. But once you get bit by the labelling bug, you may start labelling stuff around the house. I bought this one from my local office supply store.
Carlisle Folding Cart


The company that makes this
folding cart, Carlisle, sells a variety of sizes and shapes, mostly I suspect for the food service and catering industry. Turns out it's also really useful for field testing. I like this medium-sized but heavy-duty one because it's big enough to carry some serious systems under test, but folds up small enough to fit in the back of my car. It has locking wheels, so you don't see your twenty thousand dollar prototype roll away across the parking lot.
USB LTE Cellular Modem

Admittedly, this is an expensive piece of kit. But when I've needed it, I've
really needed it. I've used this
Verizon MiFi U620L LTE modem to get an internet connection on a Windows laptop when working in an airplane hanger with no WiFi. Or on a Mac laptop while parked in my car. Or on a Raspberry Pi running on a battery pack and sending telemetry to the mothership. I got this one from Verizon and added it to my cellular phone plan. The incremental cost to my plan was relatively tiny, although the device itself was pretty pricey. But sometimes it's actually
faster than the local WiFi, and likely more secure.
Raspberry Pi
Raspberry Pi TTL Serial to USB Adapter

The Raspberry Pi single board computer (SBC) is frequently useful for early prototyping of the more powerful ARM-based embedded systems. I keep one attached to my network in my home office just so I can do quick unit tests on a 64-bit ARM target.
The
FTDI TTL-232R-RPI debug cable is an off the shelf serial console to USB adapter that uses my favorite USB-to-serial solution, the FTDI chip. You can order these off Amazon. I added the "BYO 68A" label, which reminds me that the black wire goes to pin 6, the yellow wire to pin 8, and the orange wire to pin 10, on the Pi.
Ginormous Lithium Uninterruptible Power Supply


Another expensive piece of kit, this InteliCharge X1300 UPS has a big lithium battery pack that provides up to 1150Wh to 110V or 220V mains outlets, plus two USB outlets, and a 12V cigarette lighter outlet, for your portable power needs. I've run a large embedded system intended for aircraft power for hours on this unit. I bought mine from Amazon, although I notice they no longer list it; a few moments of web searching suggests it's no longer available. I have a smaller
400Wh unit from Anker that I have also used and which would be my second choice. I've used the InteliCharge to test equipment in a Faraday cage, to roll around in a parking lot to test cellular connectivity, or to move a piece of equipment around in a building without having to power it down.

This photograph shows the UPS and at least four other items from this article in use at a client's site. The UPS is powering the system under test, a laptop, and a VOIP phone. That is indeed Gigi the cat from the anime
Kiki's Delivery Service on that bag on the bottom shelf in the photograph above.
USB Charger/Battery

On a much smaller scale, devices like this
Anker PowerCore Fusion 5000, which combines a wall wart USB charger with a 5000mAh USB battery, are just the thing for powering the Raspberry Pi and similar USB-powered devices off the grid.

Here is the PowerCore plus at least five other items from this article. The battery will power the Raspberry Pi so that it can
send geolocation telemetry via the LTE modem back to the mothership.
Important safety tip: the PowerCore Fusion 5000 is
not a uninterruptible USB power supply. Disconnect the PowerCore from the mains electrical outlet and anything connected to it will notice a power disruption while the device switches to its internal battery.
Also: while I pack the Fusion in my travel kit, I learned the hard way to also bring along a convention USB wall charger - a small two-port
Anker with a foldable plug - to charge my smartphone at night as I sleep. Because the Fusion switches back and forth between charging the smartphone and charging itself, the first time I used the Fusion, my iPhone kept chiming all through the night to indicate it was now connected to a charger.
NRT ViperBoard

The embedded systems I help my clients develop always have scads of general purpose input/output (GPIO) pins used to communicate with or control sensors or devices. But often, most of the application software the team develops could be tested on a desktop personal computer or even a laptop long before a laboratory prototype is available. But such mainstream systems typically have no GPIO pins. The
ViperBoard from Nano River Technologies (NRT) solves that problem. Attach a ViperBoard via USB to your PC and suddenly you have a bunch of GPIO pins, as well as I2C and SPI serial busses. This is also useful for interfacing your PC to lab test equipment. The ViperBoard is supported right out of the box by the more recent Linux kernels. (I added the plastic standoff legs and the "2" label.)
GlobalSat USB GPS Receiver

Similarly, for products which will eventually feature geolocation, a lot of the application software could be tested on a desktop or laptop if only GPS were available. There are lots of USB GPS receivers (and I've tried
most of them), but my go-to unit is the
GlobalSat BU-353S4. Plug it into a USB port and it enumerates as a serial port. Read from the serial port and you get a stream of standard NMEA sentences providing latitude, longitude, time, and date.
(
Update 2018-12-24: I like the later
GlobalSat BU-353W10, based on the Ublox 8 chipset, even better.)
USB to Serial to USB Adapter

I've written before about my deep love for the
CableMax USB 2.0 to RS-232 DB-9 Adapter, which contains an FTDI chip, my favorite USB to serial converter. Here's an application of it that has turned out to be remarkably useful: I attached two adapters back to back with a null modem converter in between, making a device that can connect two computers via a serial connection, all via USB. This may sound mundane, but lots of embedded application software still make use of serial ports to talk to devices. This little piece of kit lets you test such software on your desktop or laptop without a serial port in sight.
SharkTap (updated 2017-06-28) (updated 2017-07-11)

I've mentioned this device before, but it bears repeating. The
SharkTap is an Ethernet tap designed for running Wireshark traces on a LAN. It supports ten megabit, one hundred megabit, and gigabit Ethernet speeds. It passes through Power over Ethernet (PoE) so it can be used on the growing number of devices (like, for me, VoIP phones) that get their power over their Ethernet connection. It is itself powered via a USB cable.

The SharkTap is conceptually dirt simple: it contains a three-port (at least) Broadcom Ethernet switch configured to pass through traffic in either direction on the (as shown here) blue and green Ethernet cables, while mirroring everything in both direction onto the red Ethernet cable.

Here's a photograph I took just moments ago of me using the SharkTap to peek at the traffic between an IoT device - a
TP-Link Mini Smart Plug - with its server - in the Amazon Web Services (AWS) cloud as it turns out - by tapping into the WAN traffic between a cable modem and a router/access point.

The SharkTap folks have introduced another model, the
SharkTapUSB, that works identically to the one I describe above, but in addition has a built-in USB 3.0 to Gigabit Ethernet interface. This greatly simplifies using laptops which lack a wired Ethernet interface (i.e. pretty much all of them), while using the same USB 3.0 connection to power the SharkTap. It worked great with my MacBook Pro, eliminating the need for me to use my Apple Thunderbolt Gigabit Ethernet adaptor.
USB Power Supply (updated 2017-07-11)

If you're like me, you have a pile of USB power supplies laying around
and you have discovered that not all USB power supplies are created equal. I like this one in particular, the
Anker PowerPort 2. It provides a maximum of 2.4A to each of two USB ports (4.8A total). It's small and its electrical plug folds away, making it easier to cram into your field kit.
Illuminated Magnifying Glass (updated 2018-05-21)

If you don't need one of these now, you eventually will. Invaluable for reading the fine print on chips, and a million other uses. I probably own close to a dozen of these, scattered around in briefcases, tool kits, work bench drawers, etc. I buy them at my local office supply store. The battery-powered LED turns off when you slide the cover closed. The specific brand or model matters less than its features and availability.
Analog Phone SIP Gateway (updated 2018-12-24)

This little device allows you to connect analog phones or even FAX machines to a VoIP service provider that supports SIP via a standard Subscriber Line Interface Circuit (SLIC). There are lots of different models and brands of these devices. I own a couple of this particular model, a
Cisco SPA112 Small Business Analog Telephone Adapter (ATA) with Router, that supports two analog lines. It costs under US$100.
As retro as it sounds, lots of the embedded telecommunication systems I work on still have analog ports. These are used to support existing legacy devices that specify a SLIC has their hardware interface. Sometimes these really are just analog phones. Sometimes they are cabin communication systems for business aircraft. Sometimes they are satellite communication systems.
Whatever they are, I need a way to test that interface in the product I'm developing
months before I have access to an actual example of the legacy device (if that indeed
ever happens before we ship an early production model cross country for integration testing). This little box lets me do that with some level of credibility and confidence. Because both the SLIC and the SIP stack are implemented by a third party, I can at least rest assured that my product successfully talks to some other device that I or a colleague didn't write ourselves.
LED Work Light (updated 2021-07-16)
The older I get, the more I appreciate having adequate light. These do the job: a battery-powered multiple-super-bright LED
work light. I bought a single one, then a pack of four, then
another pack of four. They're not much larger than a pocket penlight, with a pocket clip which has a strong magnet embedded in it. I put one in my car, in Mrs. Overclock's car, my motorcycle touring tank bag, the garage, the basement, my home office, my work briefcase, etc. No clue how long the batteries last, since I have yet to replace the three AAAs in any of them yet.
Nail Polish (updated 2022-03-29)
Nail polish turns out to be remarkably useful for marking things like correct settings on potentiometers, or the position of fasteners that should not unfasten. I just used a tiny bit this morning to mark one side of the fuel petcock knob on my Triumph Bonneville so that I can see the damn thing without my reading glasses so that the bike doesn't mysteriously stop running sixty seconds after leaving my driveway.
You may already have this in your maker kit, for those special occasions down at the club. But if not, you can find small bottles - one of which may last you your lifetime - in a staggering selection of colors. (I like bright red, but you do you.) Much like automotive touch-up paint, the bottle cap comes with its own little applicator.
Lab Assistant

It's useful to have a lab assistant to help with all the chores that come with product development and to bounce ideas off of. I've had a lot of good ones over the years. Just make sure you teach them good electro-static discharge (ESD) practices. Here you can see one of my assistants using an anti-static mat.