Here's another fun exercise from this evening class on the science, nature, and philosophy of time that I'm taking. (The instructor attributes this to Nobel prize winning physicist Kip Thorne's 1994 book Black Holes & Time Warps.)
Get three meter sticks: that's a measuring stick like a yard stick, but it's one meter long, it's divided up into one hundred centimeters, and every centimeter is divided up into ten millimeters.
Lay the first stick down on the table. There are one thousand (1,000 or 103) linear millimeters along the length defined by that stick.
Lay the second stick down on the table at a ninety degree angle to the first so that their corners touch. There are one million (1,000,000 or 106) square millimeters in the area bordered by those two sticks.
Lay the third stick orthogonally so that it stands straight up from the table and its corner touches the corners of the first two sticks. There are one billion (1,000,000,000 or 109) cubic millimeters in the volume bordered by those three sticks.
See, you thought a billion was big, didn't you? But here we are, with a billion easily measurable things just in the space on the table right in front of us.
(I was forced - FORCED, I tell you - to order three inexpensive wooden meter sticks from Amazon just so I can do this in real-life.)
Wednesday, April 25, 2018
Tuesday, April 24, 2018
Using the Open Secure Socket Layer Library in C
(Updated 2018-05-01.)
I've used the tools provided by Open Secure Socket Layer (OpenSSL), as well as third-party tools like cURL that supports OpenSSL and other SSL/TLS utilities like ssh(1) and scp(1), for years. And I've obviously spent a lot of time with hardware entropy generators, which provide the randomness crucial to using encryption securely. But I've never used the OpenSSL C API. This, despite the fact that much of my work is in the embedded realm which is very C or C++ centric.
I thought it was time to remedy that. So, in the spirit of learning by doing, I wrote a C library - Codex - that somewhat simplifies the use of encryption in communication streams for the kinds of C code I am frequently called upon to write.
But first, a disclaimer.
Cryptography, a vast complex field of endeavor, is in no way my area of expertise. I am merely a humble product developer. This article is a little bit on how Codex works, and little on how OpenSSL works, and what my experience was developing against the OpenSSL library.
Using Codex is only a little simpler than using OpenSSL.
The amount of code involved for even a simple functional test using the simpler Codex API is substantial. So instead of including code snippets, I'll just point you to the simplest examples in the repository on GitHub.
There are a lot of flavors of OpenSSL and they are all a little different.
Codex compiles and runs with
In the end, it wasn't a big deal, but it was a learning experience. And my intuition tells me that some porting will be necessary with each subsequent OpenSSL release.
OpenSSL is just one of many implementations of the Transport Layer Security (TLS) standard - which has replaced the original SSL, even though I'll continue to use the term SSL in this article. TLS itself is a moving target. TLS is defined in a growing number of Request for Comment (RFC) Internet standards documents. Architects of the TLS standard, and the developers of the libraries and tools which implement it, are in a kind of cold war with other actors on the Internet, some of whom are supported by nation states, terrorist organizations, or criminal enterprises, most with nefarious intent.
I ran Codex on several different targets and platforms.
I ran the Codex unit and functional tests with OpenSSL on the following targets and platforms.
"Nickel"
Intel NUC5i7RYH (x86_64)
Intel Core i7-5557U @ 3.10GHz x 8
Ubuntu 16.04.3 LTS "xenial"
Linux 4.10.0
gcc 5.4.0
"Lead" or "Copper"
Raspberry Pi 3 Model B (64-bit ARM)
Broadcom BCM2837 Cortex-A53 ARMv7 @ 1.2GHz x 4
Raspbian 8.0 "jessie"
Linux 4.4.34
gcc 4.9.2
"Bronze"
Raspberry Pi 2 Model B (32-bit ARM)
Broadcom BCM2836 Cortex-A7 ARMv7 @ 900MHz x 4
Raspbian 8.0 "jessie"
Linux 4.4.34
gcc 4.9.2
"Cobalt"
Raspberry Pi 3 Model B (64-bit ARM)
Broadcom BCM2837 Cortex-A53 ARMv7 @ 1.2GHz x 4
Raspbian 9.4 "stretch"
Linux 4.14.30
gcc 6.3.0
One of the approaches I used to deal with some of the need to decouple sending and receiving, since either side of the communication channel may need to send or receive independently of the other just to drive the underlying OpenSSL state machines, is to make the sides of the server asynchronous with respect to one other by using queueing.
You'll have to learn about public key infrastructure and certificates.
I've used the tools provided by Open Secure Socket Layer (OpenSSL), as well as third-party tools like cURL that supports OpenSSL and other SSL/TLS utilities like ssh(1) and scp(1), for years. And I've obviously spent a lot of time with hardware entropy generators, which provide the randomness crucial to using encryption securely. But I've never used the OpenSSL C API. This, despite the fact that much of my work is in the embedded realm which is very C or C++ centric.
I thought it was time to remedy that. So, in the spirit of learning by doing, I wrote a C library - Codex - that somewhat simplifies the use of encryption in communication streams for the kinds of C code I am frequently called upon to write.
But first, a disclaimer.
Cryptography, a vast complex field of endeavor, is in no way my area of expertise. I am merely a humble product developer. This article is a little bit on how Codex works, and little on how OpenSSL works, and what my experience was developing against the OpenSSL library.
Using Codex is only a little simpler than using OpenSSL.
The amount of code involved for even a simple functional test using the simpler Codex API is substantial. So instead of including code snippets, I'll just point you to the simplest examples in the repository on GitHub.
Here is a simple server program written using Codex: unittest-core-server.c.
Here is a client program that talks to the server: unittest-core-client.c.
Codex compiles and runs with
- OpenSSL 1.0.1, the default on Raspbian 8.0 "jessie";
- OpenSSL 1.0.2g, the default on Ubuntu 16.04.3 "xenial",
- OpenSSL 1.1.0, the default on Raspbian 9.4 "stretch";
- BoringSSL 1.1.0, Google's substantially different fork of OpenSSL; and
- OpenSSL 1.1.1, which was the current development version at the time I wrote Codex.
In the end, it wasn't a big deal, but it was a learning experience. And my intuition tells me that some porting will be necessary with each subsequent OpenSSL release.
OpenSSL is just one of many implementations of the Transport Layer Security (TLS) standard - which has replaced the original SSL, even though I'll continue to use the term SSL in this article. TLS itself is a moving target. TLS is defined in a growing number of Request for Comment (RFC) Internet standards documents. Architects of the TLS standard, and the developers of the libraries and tools which implement it, are in a kind of cold war with other actors on the Internet, some of whom are supported by nation states, terrorist organizations, or criminal enterprises, most with nefarious intent.
I ran Codex on several different targets and platforms.
I ran the Codex unit and functional tests with OpenSSL on the following targets and platforms.
"Nickel"
Intel NUC5i7RYH (x86_64)
Intel Core i7-5557U @ 3.10GHz x 8
Ubuntu 16.04.3 LTS "xenial"
Linux 4.10.0
gcc 5.4.0
"Lead" or "Copper"
Raspberry Pi 3 Model B (64-bit ARM)
Broadcom BCM2837 Cortex-A53 ARMv7 @ 1.2GHz x 4
Raspbian 8.0 "jessie"
Linux 4.4.34
gcc 4.9.2
"Bronze"
Raspberry Pi 2 Model B (32-bit ARM)
Broadcom BCM2836 Cortex-A7 ARMv7 @ 900MHz x 4
Raspbian 8.0 "jessie"
Linux 4.4.34
gcc 4.9.2
"Cobalt"
Raspberry Pi 3 Model B (64-bit ARM)
Broadcom BCM2837 Cortex-A53 ARMv7 @ 1.2GHz x 4
Raspbian 9.4 "stretch"
Linux 4.14.30
gcc 6.3.0
I did not run all OpenSSL versions on all targets and platforms. I did successfully run the server side functional test on the NUC5i7 Ubuntu x86_64 platform with the client side functional test on each of the Raspberry Pi Raspbian 32- and 64-bit ARM platforms; I felt this would be a fairly typical Internet of Things (IoT) configuration.
OpenSSL is broadly configurable, and that configuration matters.
Using TLS isn't just about using one algorithm to encrypt your internet traffic. It's about using a variety of mechanisms to authenticate the identify of the system with which you are communicating, encrypting the traffic between those systems, and protecting the resources you are using for that authentication and encryption against other actors. It's a constantly evolving process. And because every application is a little different - in terms of its needs, its available machine resources, etc. - there are a lot of trade-offs to be made. That means a lot of configuration parameters. And choosing the wrong values for your parameters can mean you burn a lot of CPU cycles for no reason, or that you leave yourself open to be hacked or spoofed by a determined adversary.
Codex has a number of OpenSSL-related configuration parameters. The defaults can be configured at build-time by changing a Makefile variables. Some of the defaults can be overridden at run-time by setters defined in a private API. Here are the defaults I chose for Codex, which gives you some idea of how complex this is:
- TLS v1.2 protocol;
- RSA asymmetric cipher with 3072-bit keys for encrypting certificates;
- SHA256 message digest cryptographic hash function for signing certificates;
- Diffie-Hellman with 2048-bit keys for exchanging keys between the peer systems;
- The symmetric cipher selected for encrypting the data stream is limited to those that conform to the Federal Information Processing Standard 140 Security Requirements for Cryptographic Modules (FIPS-140), a U. S. government computer security standard that is a common requirement in both the federal and commercial sectors.
I am pretty much depending entirely on the expertise of others to know whether these defaults make sense.
You may have to rethink how you write applications using sockets.
There are some simple helpers in Codex to assist with using the select(2) system call, which is used to multiplex sockets in Linux applications. (If you prefer poll(2) to select(2) you're mostly on your own. But on modern Linux kernels, select(2) is implemented using poll(2). I've used both, but have some preference for the select(2) API.) Multiplexing OpenSSL streams is more challenging than it might seem at first.
As the Codex functional tests demonstrate, I've multiplexed multiple SSL connections using select(2) via the Diminuto mux feature. (Diminuto is my C systems programming library upon which Codex - and many other C-based projects - is built.) But in SSL there is a lot going on under the hood. The byte stream the application reads and writes is an artifact of all the authentication and crypto going on in libssl and libcrypto. The Linux socket and multiplexing implementation in the kernel lies below all of this and knows nothing about it. So the fact that there's data to be read on the socket doesn't mean there's application data to be read. And the fact that the select(2) call in the application doesn't fire doesn't mean there isn't application data waiting to be read in a decryption buffer.
A lot of application reads and writes may merely be driving the underlying SSL protocol and its associated state machines. OpenSSL doesn't read or write on the socket of its own accord; it relies on the application to do so by making the appropriate API calls. A read(2) on a socket may return zero application data, but will have satisfied some need on the part of OpenSSL. Zero application data doesn't mean the far end closed the socket.
Hence multiplexing isn't as useful as it might seem, and certainly not as easy as in non-OpenSSL applications. A multi-threaded server approach, which uses blocking reads and writes, albeit less scalable, might ultimately be more useful. But as the functional tests demonstrate, multiplexing via select(2) can be done. It's just a little more complicated.
I should especially make note that my functional tests pass a lot of data - several gigabytes - and the application model I'm using almost always has data that needs to be written or read on the socket. What I don't test well in Codex are circumstances in which the SSL protocol needs reads or writes on the socket but the application itself doesn't have any need to do so. This can happen routinely in other patterns of application behavior.
Codex tries to deal with this by implementing its own state machines that can figure out when OpenSSL needs a additional read or a write from the API return codes. I'm not convinced I've adequately tested this, nor indeed have I figured out how to adequately test it.
Here is a state machine server program written using Codex: unittest-machine-server.c.
One of the approaches I used to deal with some of the need to decouple sending and receiving, since either side of the communication channel may need to send or receive independently of the other just to drive the underlying OpenSSL state machines, is to make the sides of the server asynchronous with respect to one other by using queueing.
Here is a queueing server program written using Codex: unittest-handshake-server.c.
Here is a client program that talks to the server: unittest-handshake-client.c.
You'll have to learn about public key infrastructure and certificates.
Certificates are the "identity papers" used by systems using TLS to prove that they are who they say they are. But like identity papers like passports and drivers licenses, certificates can be forged. So a certificate for Alice (a computer, for example) will be cryptographically signed using a certificate containing a private key for Bob, whose public key is known. The idea is if you can trust Bob, then you can trust Alice. But what if you don't know Bob? Bob's certificate may be cryptographically signed using a certificate containing a private key for Dan, whose public key is known. And maybe you know and trust Dan. This establishes a certificate chain, as in a "chain of trust". The final certificate at the end of the chain is the root certificate, as in the "root of trust."
At some point the chain has contain a certificate from someone you know and trust. This is often the root certificate, but it might be one of the intermediate certificates. Typically this trusted certificate is that of a certificate authority (CA), a company or organization that does nothing but sign and distribute trusted certificates to system administrators to install on their servers. Whether you realize it or not, every time you access a secure server at, say, Amazon.com, using a Uniform Resource Locator (URL) - that is, you click on a web link that begins with https: - all this is going on under the hood.
All the stuff necessary to store, manage, revoke (because that's a thing), and authenticate certificates in a certificate chain is called a Public Key Infrastructure (PKI). Codex implements just enough PKI to run its unit and functional tests. All of the Codex root certificates are self-signed; Codex acts as its own certificate authority. This is okay for the functional tests, but is in no way adequate for actually using Codex in a real-life application.
The Makefile for Codex builds simulated root, certificate authority (CA), client, and server certificates for the functional tests. It is these certificates that allow clients to authenticate their identities to servers and vice versa. (The Makefile uses both root and CA certificates just to exercise certificate chaining.)
These are the certificates that the Codex build process creates for testing, just to give you an idea of what's involved in a PKI:
- bogus.pem is signed by root with an invalid Common Name (CN) identifying the owner;
- ca.pem is a CA certificate for testing chaining;
- client.pem is signed by the root certificate for client-side tests;
- self.pem is a self-signed certificate with no root to test rejection of such certificates;
- server.pem is signed by root and CA for server-side tests;
- revoked.pem has a serial number in the generated list of revoked certificates;
- revokedtoo.pem has a serial number in the list of revoked certificates;
- root.pem is a root certificate.
Because a lot of big-time encryption is involved in creating the necessary PKI, public and private keys, and certificates, this step can take a lot of CPU time. This can take many minutes on a fast CPU, or tens of minutes or even longer on a slower system. Fortunately it only needs to be done once per system during the build process.
To run Codex between different computers, they have to trust one another.
When building Codex on different computers - like my Intel server and my Raspberry Pi ARM clients - and then running the tests between those computers, the signing certificates (root, and additional CA if it is used) for the far end have to be something the near end trusts. Otherwise the SSL handshake between the near end and the far end fails (just like it's supposed to).
The easiest way to do this for testing is to generate the root and CA credentials on the near end (for example, the server end), and propagate them to the far end (the client end) before the far end credentials are generated. Then those same root and CA credentials will be used to sign the certificates on the far end during the build, making the near end happy when they are used in the unit tests. This is basically what occurs when you install a root certificate using your browser, or generate a public/private key pair so that you can use ssh(1) and scp(1) without entering a password - you are installing shared credentials trusted by both peers.
The Codex Makefile has a helper target that uses ssh(1) and scp(1) to copy the near end signing certificates to the far end where they will be used to sign the far end's credentials when you build the far end. This helper target makes some assumptions about the far end directory tree looking something like the near end directory tree, at least relative to the home directory on either end.
Codex is deliberately picky about the certificates on the far end.
In addition to using the usual OpenSSL verification mechanisms, Codex provides an additional verification function that may be invoked by the application. The default behavior for accepting a connection from either the server or the client is as follows.
Codex rejects self-signed certificates, unless this requirement is explicitly disabled at build time in the Makefile or at run-time through a setter in the private API. This is implemented through the standard OpenSSL verification call back.
If the application chooses to initialize Codex with a list of revoked certificate serial numbers (this is a thing), Codex requires that every certificate in a certificate chain have a serial number that is not revoked. This is implemented through the standard OpenSSL verification call back.
Codex requires that either the Common Name (CN) or the Fully-Qualified Domain Name (FQDN), encoded in a certificate, match the expected name the application provides to the Codex API (or the expected name is null, in which case Codex ignores this requirement). The expected name can be a wildcard domain name like *.prairiethorn.org, which will have to be encoded in the far end system's certificate.
Codex expects a DNS name encoded in the certificate in a standards complaint fashion. Multiple DNS names may be encoded. At least one of these DNS names must resolve to the IP address from which the SSL connection is coming.
It is not required that the FQDN that matches against the expected name be the same FQDN that resolves via DNS to an IP address of the SSL connection. The server may expect *.prairiethorn.org, which could be either the CN or a FQDN entry in the client certificate, but the certificate will also have multiple actual DNS-resolvable FQDNs like alpha.prairiethorn.org, beta.prairiethorn.org, etc.
It is also not required that if a peer connects with both an IPv4 and an IPv6 address (typically it will), that they match the same FQDN specified in the certificate, or that both of the IPv4 and the IPv6 address matches. Depending on how /etc/host is configured on a peer, its IPv4 DNS address for localhost could be 127.0.0.1, and its IPv6 DNS address for localhost can legitimately be either ::ffff:127.0.0.1 or ::1. The former is an IPv4 address cast in IPv6-compatible form, and the latter is the standard IPv6 address for localhost. Either is valid.
If the peer named localhost connects via IPv4, its far end IPv4 address as seen by the near end will be 127.0.0.1 and its IPv6 address will be ::ffff:127.0.0.1. If it connects via IPv6, its far end IPv4 address may be 0.0.0.0 (because there is no IPv4-compatible form of its IPv6 address) and its far end IPv6 address will be ::1. The /etc/host entry for localhost may be 127.0.0.1 (IPv4), or ::1 (IPv6), or both.
Furthermore, for non-local hosts, peers don't always have control of whether they connect via IPv4 or IPv6, depending on what gateways they may pass through. Finally, it's not unusual for the IPv4 and IPv6 addresses for a single host to be given different fully-qualified domain names in DNS, for example alpha.prairiethorn.org for IPv4 and alpha-6.prairiethorn.org for IPv6; this allows hosts trying to connect to a server to be able to select the IP version by using a different host name when it is resolved via DNS.
Certificates can be revoked, because sometimes stuff happens.
Codex does not directly support signed certificate revocation lists (CRLs), nor the real-time revocation of certificates using the Online Certificate Status Protocol (OCSP). It will however import a simple ASCII list of hexadecimal certificate serial numbers, and reject any connection whose certificate chain has a serial number on that list. The Codex revocation list is a simple ASCII file containing a human readable and editable list of serial numbers, one per line. Here is an example.
9FE8CED0A7934174
9FE8CED0A7934175
The serial numbers are stored in-memory in a red-black tree (a kind of self-balancing binary tree), so the search time is relatively efficient.
So you can use the tools of your PKI implementation to extract the serial numbers from revoked certificates and build a list that Codex can use. OCSP is probably better for big applications, but I wonder if we'll see it used in small IoT applications.
OpenSSL is a lot faster than I expected.
Although generating the certificates during the Codex build for the functional tests takes a long (sometimes very long) time, and there is some overhead initially during the functional tests with the certificate exchange, once the keys are exchanged the communication channel uses symmetric encryption and that runs pretty quickly.
There are a number of scripts I used to do some performance testing by comparing the total CPU time of encrypted and unencrypted functional tests for various workloads and configurations. I then used R and Excel to post-process the data. This is even more a work in progress than the rest of this effort, but so far has yielded no surprising insights.
I also used Wireshark to spy on the encrypted byte stream between two systems running a functional test.
Just to verify that I wasn't blowing smoke and kidding myself about what I was doing, I ran a Codex functional test against an openssl s_client command. That verified that at least a tool I didn't write agreed with what I thought was going on.
There is a lot going on here.
But we might as well get used to it. Many service providers that support IoT applications already require that the communication channels between clients and servers be encrypted. That's clearly going to be the rule, not the exception, in the future.
Acknowledgements
I owe a debt of gratitude to my former Bell Labs office mate Doug Gibbons who has a deep well of experience in this topic of which he generously shared only a tiny portion with me.
Repositories
https://github.com/openssl/openssl
https://boringssl.googlesource.com/boringssl
https://github.com/coverclock/com-diag-codex
https://github.com/coverclock/com-diag-diminuto
References
D. Adrian, et al., "Imperfect Forward Secrecy: How Diffie-Hellman Fails in Practice", 22nd ACM Conference on Computer and Communication Security, 2015-10, https://weakdh.org/imperfect-forward-secrecy-ccs15.pdf
K. Ballard, "Secure Programming with the OpenSSL API", https://www.ibm.com/developerworks/library/l-openssl/, IBM, 2012-06-28
E. Barker, et al., "Transitions: Recommendation for Transitioning the Use of Cryptographic Algorithms and Key Lengths", NIST, SP 800-131A Rev. 1, 2015-11
D. Barrett, et al., SSH, The Secure Shell, 2nd ed., O'Reilly, 2005
D. Cooper, et al., "Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile", RFC 5280, 2008-05
J. Davies, Implementing SSL/TLS, Wiley, 2011
A. Diquet, "Everything You've Always Wanted to Know About Certificate Validation with OpenSSL (but Were Afraid to Ask)", iSECpartners, 2012-10-29, https://github.com/iSECPartners/ssl-conservatory/blob/master/openssl/everything-you-wanted-to-know-about-openssl.pdf?raw=true
Frank4DD, "certserial.c", 2014, http://fm4dd.com/openssl/certserial.htm
V. Geraskin, "OpenSSL and select()", 2014-02-21, http://www.past5.com/tutorials/2014/02/21/openssl-and-select/
M. Georgiev, et. al., "The Most Dangerous Code in the World: Validating SSL Certificates in Non-Browser Software", 19nd ACM Conference on Computer and Communication Security (*CCS'12), Raleigh NC USA, 2012-10-16..18, https://www.cs.utexas.edu/~shmat/shmat_ccs12.pdf
D. Gibbons, personal communication, 2018-01-17
D. Gibbons, personal communication, 2018-02-12
D. Gillmor, "Negotiated Finite Diffie-Hellman Ephemeral Parameters for Transport Layer Security (TLS)", RFC 7919, 2016-08
HP, "SSL Programming Tutorial", HP OpenVMS Systems Documentation, http://h41379.www4.hpe.com/doc/83final/ba554_90007/ch04s03.html
Karthik, et al., "SSL Renegotiation with Full Duplex Socket Communication", Stack Overflow, 2013-12-14, https://stackoverflow.com/questions/18728355/ssl-renegotiation-with-full-duplex-socket-communication
V. Kruglikov et al., "Full-duplex SSL/TLS renegotiation failure", OpenSSL Ticket #2481, 2011-03-26, https://rt.openssl.org/Ticket/Display.html?id=2481&user=guest&pass=guest
OpenSSL, documentation, https://www.openssl.org/docs/
OpenSSL, "HOWTO keys", https://github.com/openssl/openssl/blob/master/doc/HOWTO/keys.txt
OpenSSL, "HOWTO proxy certificates", https://github.com/openssl/openssl/blob/master/doc/HOWTO/proxy_certificates.txt
OpenSSL, "HOWTO certificates", https://github.com/openssl/openssl/blob/master/doc/HOWTO/certificates.txt
OpenSSL, "Fingerprints for Signing Releases", https://github.com/openssl/openssl/blob/master/doc/fingerprints.txt
OpenSSL Wiki, "FIPS mode and TLS", https://wiki.openssl.org/index.php/FIPS_mode_and_TLS
E. Rescorla, "An Introduction to OpenSSL Programming (Part I)", Version 1.0, 2001-10-05, http://www.past5.com/assets/post_docs/openssl1.pdf (also Linux Journal, September 2001)
E. Rescorla, "An Introduction to OpenSSL Programming (Part II)", Version 1.0, 2002-01-09, http://www.past5.com/assets/post_docs/openssl2.pdf (also Linux Journal, September 2001)
I. Ristic, OpenSSL Cookbook, Feisty Duck, https://www.feistyduck.com/books/openssl-cookbook/
I. Ristic, "SSL and TLS Deployment Best Practices", Version 1.6-draft, Qualys/SSL Labs, 2017-05-13, https://github.com/ssllabs/research/wiki/SSL-and-TLS-Deployment-Best-Practices
L. Rumcajs, "How to perform a rehandshake (renegotiation) with OpenSSL API", Stack Overflow, 2015-12-04, https://stackoverflow.com/questions/28944294/how-to-perform-a-rehandshake-renegotiation-with-openssl-api
J. Viega, et al., Network Security with OpenSSL, O'Reilly, 2002
J. Viega, et al., Secure Programming Cookbook for C and C++, O'Reilly, 2003
Acknowledgements
I owe a debt of gratitude to my former Bell Labs office mate Doug Gibbons who has a deep well of experience in this topic of which he generously shared only a tiny portion with me.
Repositories
https://github.com/openssl/openssl
https://boringssl.googlesource.com/boringssl
https://github.com/coverclock/com-diag-codex
https://github.com/coverclock/com-diag-diminuto
References
D. Adrian, et al., "Imperfect Forward Secrecy: How Diffie-Hellman Fails in Practice", 22nd ACM Conference on Computer and Communication Security, 2015-10, https://weakdh.org/imperfect-forward-secrecy-ccs15.pdf
K. Ballard, "Secure Programming with the OpenSSL API", https://www.ibm.com/developerworks/library/l-openssl/, IBM, 2012-06-28
E. Barker, et al., "Transitions: Recommendation for Transitioning the Use of Cryptographic Algorithms and Key Lengths", NIST, SP 800-131A Rev. 1, 2015-11
D. Barrett, et al., SSH, The Secure Shell, 2nd ed., O'Reilly, 2005
D. Cooper, et al., "Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile", RFC 5280, 2008-05
J. Davies, Implementing SSL/TLS, Wiley, 2011
A. Diquet, "Everything You've Always Wanted to Know About Certificate Validation with OpenSSL (but Were Afraid to Ask)", iSECpartners, 2012-10-29, https://github.com/iSECPartners/ssl-conservatory/blob/master/openssl/everything-you-wanted-to-know-about-openssl.pdf?raw=true
Frank4DD, "certserial.c", 2014, http://fm4dd.com/openssl/certserial.htm
V. Geraskin, "OpenSSL and select()", 2014-02-21, http://www.past5.com/tutorials/2014/02/21/openssl-and-select/
M. Georgiev, et. al., "The Most Dangerous Code in the World: Validating SSL Certificates in Non-Browser Software", 19nd ACM Conference on Computer and Communication Security (*CCS'12), Raleigh NC USA, 2012-10-16..18, https://www.cs.utexas.edu/~shmat/shmat_ccs12.pdf
D. Gibbons, personal communication, 2018-01-17
D. Gibbons, personal communication, 2018-02-12
D. Gillmor, "Negotiated Finite Diffie-Hellman Ephemeral Parameters for Transport Layer Security (TLS)", RFC 7919, 2016-08
HP, "SSL Programming Tutorial", HP OpenVMS Systems Documentation, http://h41379.www4.hpe.com/doc/83final/ba554_90007/ch04s03.html
Karthik, et al., "SSL Renegotiation with Full Duplex Socket Communication", Stack Overflow, 2013-12-14, https://stackoverflow.com/questions/18728355/ssl-renegotiation-with-full-duplex-socket-communication
V. Kruglikov et al., "Full-duplex SSL/TLS renegotiation failure", OpenSSL Ticket #2481, 2011-03-26, https://rt.openssl.org/Ticket/Display.html?id=2481&user=guest&pass=guest
OpenSSL, documentation, https://www.openssl.org/docs/
OpenSSL, "HOWTO keys", https://github.com/openssl/openssl/blob/master/doc/HOWTO/keys.txt
OpenSSL, "HOWTO proxy certificates", https://github.com/openssl/openssl/blob/master/doc/HOWTO/proxy_certificates.txt
OpenSSL, "HOWTO certificates", https://github.com/openssl/openssl/blob/master/doc/HOWTO/certificates.txt
OpenSSL, "Fingerprints for Signing Releases", https://github.com/openssl/openssl/blob/master/doc/fingerprints.txt
OpenSSL Wiki, "FIPS mode and TLS", https://wiki.openssl.org/index.php/FIPS_mode_and_TLS
E. Rescorla, "An Introduction to OpenSSL Programming (Part I)", Version 1.0, 2001-10-05, http://www.past5.com/assets/post_docs/openssl1.pdf (also Linux Journal, September 2001)
E. Rescorla, "An Introduction to OpenSSL Programming (Part II)", Version 1.0, 2002-01-09, http://www.past5.com/assets/post_docs/openssl2.pdf (also Linux Journal, September 2001)
I. Ristic, OpenSSL Cookbook, Feisty Duck, https://www.feistyduck.com/books/openssl-cookbook/
I. Ristic, "SSL and TLS Deployment Best Practices", Version 1.6-draft, Qualys/SSL Labs, 2017-05-13, https://github.com/ssllabs/research/wiki/SSL-and-TLS-Deployment-Best-Practices
L. Rumcajs, "How to perform a rehandshake (renegotiation) with OpenSSL API", Stack Overflow, 2015-12-04, https://stackoverflow.com/questions/28944294/how-to-perform-a-rehandshake-renegotiation-with-openssl-api
J. Viega, et al., Network Security with OpenSSL, O'Reilly, 2002
J. Viega, et al., Secure Programming Cookbook for C and C++, O'Reilly, 2003
Monday, April 23, 2018
A Menagerie of GPS Devices
I've had several occasions to make use of Global Navigation Satellite System (GNSS) receivers that emit National Marine Equipment Association (NMEA) serial output. For most of these devices, the NMEA output is funneled through a Universal Serial Bus (USB) interface. Others do so wirelessly via Bluetooth. Some have an actual RS232 serial port, or logic level serial output. In this article I briefly describe these devices, what I've used them for, and give you some useful information about each. All of these devices have been used with my own GNSS software.
Such devices are not appropriate for the the kinds of precision timing applications I described in Engines of Time; my attempt to do so quickly revealed the latency and jitter that the serial-to-USB conversion introduces, and that is deadly to Network Time Protocol (NTP) applications. But GPS-over-USB devices are really useful for quickly cobbling together a geolocation application like I described in Better Never Than Late, or for determining the general time-of-day at least to the nearest second.
A quick search for "GPS USB" on Amazon.com reveals a pile of such devices (and lots of other stuff). Most are pretty inexpensive: a few tens of dollars, if that. This turned out to be really useful when I was working on Hazer, a simple little C library to parse NMEA GPS sentences. My tiny little company ended up buying a large assortment of these devices - ten in all, plus a few other more special purpose GPS devices that didn't have USB interfaces - allowing me to test Hazer against a broad range of of NMEA sentences. (There were a few surprises here and there.)
All of these devices emit ASCII data in a standard format described in the document NMEA 0183 Standard for Interfacing Marine Electronic Devices (version 4.10, NMEA 0183, National Marine Electronics Association, 2012-06). While NMEA charges a hefty fee (hundreds of dollars) for the document, summaries are available for the price of a little web search fu. Typical NMEA output looks like this.
Because all the NMEA output is in ASCII, and the devices manifest as serial devices, you can play with them using your favorite terminal program, like screen for MacOS or Linux, or PuTTY on Windows.
Each sentence begins with a dollar sign and is terminated by an asterisk, with a simple checksum like 77, and carriage return/line feed pair. The NMEA application - GPS in this case, since there are other devices that emit other kinds of NMEA data - is identified with a GP, and its specific content by another token like, here, RMC, GGA, and GSV. Different sentences carrying different payloads, like the time of day in Universal Coordinated Time (UTC), current position in latitude and longitude expressed in degrees and decimal minutes, from exactly which satellites the position fix was derived, and the computed error in that position fix based on the orbital position of those satellites.
Why did I write Hazer to parse NMEA GPS sentences when there is plenty of perfectly usable open source code to do just that? In fact, I've used the most excellent open source GPS Daemon (gpsd) in all of my precision timing projects, as described in various articles like My WWVB Radio Clock. But as I'm fond of saying, I only learn by doing, and my goal with Hazer was to learn how NMEA GPS sentences were encoded. That turned out to be unexpectedly useful, as I've used what I've learned, and sometimes used Hazer itself, in a number of other projects, including one where I used gpsd as well.
All of the inexpensive GPS USB devices that I tested with Hazer use one of the following GPS chipsets.
Most of these devices have an integrated patch antenna. As you will see in the photographs, a few required a separate amplified antenna in which the power was carried in-band over the coxial connection.
I didn't test the accuracy of any of these devices. But since they are all based on the a relatively small number of commercial GPS chipsets, a little web searching will yield useful information. All of these devices produced standard ASCII NMEA sentences that were easily usable by Hazer.
(Update 2019-11-25) I've tested all of the GPS/GNSS receivers shown in this article with my own software. The hosts used for testing vary widely depending on the application. They are all listed in the README for the Hazer repository.
Most of these GPS devices already had udev rules in whichever Ubuntu distribution to which I was connecting them. This allowed them to hot plug and automatically and instantiate a serial port in the /dev directory, like /dev/ttyUSB0 (a raw USB serial device) or /dev/ttyACM0 (an Abstract Control Module serial device). A couple required some additional udev fu and those rules can be found in in GitHub.
Below is a list of the GPS USB devices, plus some others with other interfaces, that I used to test Hazer. For each, where possible, I identify the GPS chipset, the serial chipset, how often they generate an updated location, and some useful information regarding how to interface the device to a test system. If you are using any of these devices, or are trying to decide which to purchase, you may find this information useful.
USGlobalSat BU-353S4
This is an excellent unit for everyday general-purpose geolocation use. It is relatively inexpensive and easily available from a variety of outlets. This device's slower baud rate - 4800 baud - is actually an advantage for applications that integrate it with the real-time GPS feature of Google Maps Pro. (Updated 2018-08-27: the name of this company appears to have changed recently from USGlobalSat to GlobalSat.)

GPS chipset: SiRF Star IV
Serial chipset: Prolific
Serial parameters: 4800 8N1
udev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 1Hz
USGlobalSat ND-105C

GPS chipset: SiRF Star III
Serial chipset: Prolific
Serial parameters: 4800 8N1
udev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 1Hz
USGlobalSat BU-353S4-5Hz
Like the other similar USGlobalSat unit but with a higher sentence frequency. (2018-08-27: the name of this company appears to have changed recently to from USGlobalSat to GlobalSat.)

GPS chipset: SiRF Star IV
Serial chipset: Prolific
Serial parameters: 115200 8N1
udev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 5Hz
Stratux Vk-162 Gmouse

GPS chipset: U-Blox 7
Serial chipset: integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: v1546p01A7
Device name: ttyACM
Update frequency: 1Hz
Eleduino Gmouse

GPS chipset: U-Blox 7
Serial chipset: integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: v1546p01A7
Device name: ttyACM
Update frequency: 1Hz
Generic Gmouse
(That is how it was listed on Amazon.com.)

GPS chipset: U-Blox 7
Serial chipset: integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: v1546p01A7
Device name: ttyACM
Update frequency: 1Hz
Pharos GPS-360

GPS chipset: SiRF Star II
Serial chipset: Prolific (likely integrated into provided cable)
Serial parameters: 4800 8N1
udev Vendor/Product id: v067BpAAA0
Device name: ttyUSB
Update frequency: 1Hz
Pharos GPS-500

GPS chipset: SiRF Star III
Serial chipset: Prolific (likely in provided dongle)
Serial parameters: 4800 8N1
udev Vendor/Product id: v067BpAAA0
Device name: ttyUSB
Update frequency: 1Hz
MakerFocus USB-Port-GPS
Shown attached to a Raspberry Pi as part of a larger project in which I integrated Hazer with Google Earth to create a moving map display. Supports 1PPS over a digital output pin.

GPS chipset: Quectel L80-R
Serial chipset: Cygnal (based on Vendor ID)
Serial parameters: 9600 8N1
udev Vendor/Product id: v10C4pEA60
Device name: ttyUSB
Update frequency: 1Hz
Sourcingbay GM1-86

GPS chipset: U-Blox 7
Serial chipset: probably integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: p1546v01A7
Device name: ttyACM
Update frequency: 1Hz
Uputronics Raspberry Pi GPS Expansion Board v4.1
Shown in a Raspberry Pi stack as part of Hourglass, a GPS-disciplined NTP server; it's the board with the SMA connector extending out the bottom to which a coaxial cable to an active antenna is attached.

GPS chipset: U-Blox 8 (MAX-M8Q)
Serial chipset: N/A (logic-level serial)
Serial parameters: 9600 8N1
udev Vendor/Product id: N/A
Device name: ttyAMA
Update frequency: 1Hz
Jackson Labs Technologies CSAC GPSDO
This is a breathtakingly expensive part, shown upper right as part of Astrolabe, an NTP server with a GPS-disciplined oscillator (GPSDO) that includes a cesium chip-scale atomic clock (CSAC).

GPS chipset: U-Blox 6 (LEA-6T)
Serial chipset: N/A (RS232 serial)
Serial parameters: 115200 8N1
udev Vendor/Product id: N/A
Device name: ttyACM
Update frequency: 1Hz
Garmin GLO
Purchased for and works well with Android GPS applications like the ones I routinely use with my Google Pixel C Android tablet.

GPS chipset: unknown
Serial chipset: N/A (Bluetooth)
Serial parameters: N/A
udev Vendor/Product id: N/A
Device name: rfcomm
Update frequency: 10Hz
NaviSys Technology GR-701W (added 2018-05-04)
Supports a One Pulse Per Second (1PPS) signal by asserting DCD on the simulated serial port. Receives WAAS augmentation too. Can be used to build small GPS-disciplined NTP servers like Candleclock. The USB interface jitters the timing enough that it's my least precise NTP server, but it is still better than no local NTP server at all. It's available on Etsy.

GPS chipset: U-Blox 7
Serial chipset: Prolific
Serial parameters: 9600 8N1
dev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 1Hz
TOPGNSS GN-803G (added 2018-08-08)
Has multiple RF stages so that it can receive more than one GNSS frequency at a time. Supports GPS, QZSS, GLONASS, and BEIDOU. By default, receives GPS and GLONASS and computes ensemble fixes. Supports WAAS, EGNOS, MSAS. Has seventy-two channels. A remarkable device for its price.

GPS chipset: U-Blox 8 (UBX-M8030-KT)
Serial chipset: U-Blox 8
Serial parameters: 9600 8N1
dev Vendor/Product id: v1546p01A8
Device name: ttyACM
Update frequency: 1Hz
GlobalSat BU-353W10 (added 2018-08-27)
Like the GN-803G above, this device uses the U-Blox 8 chipset, and so it has the multiple RF stages and computes ensemble fixes using GPS and GLONASS plus WAAS. It's a few dollars more than the GN-803G, but is available from Amazon.com with two-day shipping, where as I ordered the GN-803G from eBay and it was shipped from China. One interesting difference is that the GN-803G updates the satellite view (via NMEA GSV sentences) once per second, but the BU-353W10 updates the view every five seconds; the position fix and list of active satellite is still updated once a second. Since this device has advanced features I crave, and is easily acquired, it will likely be my go-to USB GPS device going forward (unless I need special features it doesn't have, like 1PPS).

GPS chipset: U-Blox 8 (UBX-M8030)
Serial chipset: U-Blox 8
Serial parameters: 9600 8N1
dev Vendor/Product id: v1546p01A8
Device name: ttyACM
Update frequency: 1Hz
Ardusimple SimpleRTK2B (updated 2019-02-24)
The SimpleRTK2B is an Arduino-compatible shield which can be used standalone, as I have done below, without headers through its USB-to-serial interface which also provides power. The SimpleRTK2B is based on the U-Blox ZED-F9P chip. This U-Blox 9 chip is remarkable in that it has all the goodness of the U-Blox 8, but also has the RF hardware and decode capability to receive not only GPS (U.S.) and GLONASS (Russia) signals, but also Galileo (E.U.) and Beidou (China). And it trivially does so, without any work on my part. Right out of the box, it computes an ensemble fix based on pseudo-ranges from all four constellations, and tries to use at least four satellites when possible from each constellation to do so. I suspect this makes it much more resistant to jamming and spoofing.
The device also supports Real-Time Kinematics (RTK), where two GPS receivers exchange information in the form of Radio Technical Commission for Maritime services (RTCM) messages, allowing built-in algorithms to potentially compute much more precise position fixes.

To receive signals from the four different constellations requires a multiband active antenna. The one I used is about the size of a hockey puck.

GPS chipset: U-Blox 9 (ZED-F9P)
Serial chipset: U-Blox 9
Serial parameters: 38400 8N1
dev Vendor/Product id: v1546p01A9
Device name: ttyACM
Update frequency: 1Hz
SparkFun GPS-RTK2 (updated 2019-07-12, 2019-11-25)
This is SparkFun's take on the same U-Blox 9 chip as is used in the Ardusimple SimpleRTK2B board. It lacks the Digi radio integration (which I ended up not using anyway). It has a USB-C port instead of a micro-B port. It provides a lithium battery to maintain memory on the receiver which might improve your chances of doing a hot start. Also, it ships from Boulder Colorado - a half hour or so drive from me - instead of from Barcelona Spain. So far it seems to function identically with Hazer, and its sister projects Yodel and Tumbleweed, as the SimpleRTK2B.

Below is a GPS-RTK2 board in an improvised case (a tiny 0.07 liter Really Useful Box from the office supply store; I've also used the 0.14 liter version), with a helical multi band active antenna. I used a Dremel tool to make holes for the USB connector, the antenna connector, and to mount the board to the bottom of the case using nylon standoffs. Side by side testing has shown the helical antenna to be less sensitive to weak signals than others I've used, but it is supposed to be less dependent on physical orientation (good for applications like drones).

Below is the GPS-RTK2 with the helical antenna in the window of my home office. Behind it is the hockey puck GNSS antenna mentioned above on a gimbaled camera mount with a steel ground plate (painted orange), and behind that, two marine GPS antennas. (When I took this photograph I had a total of eight GPS/GNSS antennas in my window, each connected to an active receiver.)

GPS chipset: U-Blox 9 (ZED-F9P)
Serial chipset: U-Blox 9
Serial parameters: 38400 8N1
dev Vendor/Product id: v1546p01A9
Device name: ttyACM
Update frequency: 1Hz
Software Defined Radio (updated 2019-02-05)
If you had any doubt as to the amazing capabilities of devices like the GlobalSat BU-353W10 GPS USB dongle described above - or any other consumer device that uses the Ublox 8 chipset - try duplicating it using a software defined radio (SDR) and open source software. My experience is I can get a small fraction of the performance of that US$40 device for about one hundred times its price and manydays weeks of my time. And that doesn't include the cost of the several failed attempts on my part using other less expensive components. I sense my ham radio friends laughing.
For sure your mileage may vary. My experience in this domain (which was hard won for me, not being a radio frequency guy, nor a signal processing guy, nor even a hardware guy) was that the performance of the GPS SDR depends on a bunch of environmental factors over which I have little or no control, like the weather (snowing == bad), or even time of day (sun == bad). After a long expensive learning experience, I am sometimes - but with no consistency or reliability - able to get a position fix. It is entirely possible that with more learning and less ignorance on my part, this setup could work a lot better. This is definitely a work in progress, although it is progressing very slowly.
Here's a photograph of my hardware.

After several false starts, I ended up using the Ettus Research B210 Universal Software Radio Peripheral (USRP). The B210 has a 12-bit analog to digital convertor - cheaper units use an 8-bit ADC - which I found was important for the SDR to be able to discriminate the GPS signals, which are so weak as to be barely detectable from the background radio noise. It has a USB 3.0 interface, which has been useful for the system to keep up with the fire hose of data from the B210. The B210 can be completely bus powered over the USB cable, which will be useful when I truck this around the neighborhood, as I am prone to do. I also opted to equip my B210 with an optional GPS-disciplined oscillator (GPSDO), that includes a temperature compensated crystal oscillator (TCXO), to use as a precision frequency source. That means I had to provide two GPS antennas, one for my GPS SDR, and one for the hardware GPS receiver. The irony of using a hardware GPS receiver to implement a software GPS receiver is not lost on me. The B210 is the cream colored box with the SMA connectors in the photograph above.
The B210 doesn't provide a bias tee (some radios do), a device that allows you to provide power over the coaxial cable to a GPS antenna that contains active elements in the form of a low noise amplifier. An LNA is necessary to boost the signals, which can be so weak as to be defeated just by the loss over the coax cable between the antenna and the radio. I tried several different bias tees (they aren't expensive, relatively speaking) before I settled on the little red device in the photograph, a CrysTek Microwave CBTEE-01-50-6000. I broke out my soldering iron to hand-fabricate the USB-to-SMA cable that powers the bias tee. (Update 2019-02-04: I've been trying other bias tees since then.)
The same false starts led me to successively upgrade the computer I used as my host for running the GNU Radio and GNSS-SDR open source projects, finally settling on an Intel NUC7i7BNH. This NUC is a physically small but extremely powerful computer with multiple Intel i7 cores each sustaining a 3.5GHz clock rate. The data and signal processing horsepower required for real-time SDR in general, and for GPS in particular, is significant. That became evident as slower systems couldn't at first even keep up with the USB data stream from the receiver, then couldn't lock on any of the satellites, then couldn't maintain lock long enough to acquire the minimum of four satellites necessary to compute a position fix. The NUC is the black box with the two USB cables coming out the front, one to the USRP, the other to the bias tee. It runs Ubuntu Linux.
The window of my home office now has eight GPS antennas sitting on the sill. Here are the two I used for my SDR.

I used two active 5V GPS antennas. I lovingly hand-crafted the dual setup (one for the SDR, one for the GPSDO) using two camera-tripod-style gimbaled mounts. Each mount has a ground plane, a conducting surface - here, a hunk of steel weighting about a quarter pound each - that has a radius of at least a quarter of a wavelength. The ground plane simulates the earth ground and serves to reflect the radio waves back into the antenna. I have no clue how necessary these are, but they were just a few bucks each.
The code name for this project is "Critter" and the repository containing the scripts and configuration files I used to implement it can be found on GitHub.
I used the command
# gnss-sdr --config_file=../etc/gnss-b210-a.conf --log_dir=.
to run my GPS SDR, using a GNSS-SDR configuration file (update: whose name has since changed) that can be found in the repository for my project code-named Critter. Below is the output of one of my successful attempts.
NAV Message: received subframe 5 from satellite GPS PRN 31 (Block IIR-M)
NAV Message: received subframe 5 from satellite GPS PRN 32 (Block IIF)
NAV Message: received subframe 5 from satellite GPS PRN 10 (Block IIF)
Current input signal time = 125 [s]
Current input signal time = 126 [s]
Current input signal time = 127 [s]
Current input signal time = 128 [s]
Current input signal time = 129 [s]
Current input signal time = 130 [s]
NAV Message: received subframe 1 from satellite GPS PRN 31 (Block IIR-M)
NAV Message: received subframe 1 from satellite GPS PRN 32 (Block IIF)
NAV Message: received subframe 1 from satellite GPS PRN 18 (Block IIR)
NAV Message: received subframe 1 from satellite GPS PRN 10 (Block IIF)
Current input signal time = 131 [s]
First position fix at 2018-Dec-28 18:41:19 UTC is Lat = 39.7941 [deg], Long = -105.153 [deg], Height= 1713.42 [m]
The RINEX Navigation file header has been updated with UTC and IONO info.
Position at 2018-Dec-28 18:41:19 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1693.18 [m]
Current input signal time = 132 [s]
Position at 2018-Dec-28 18:41:19 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1704.55 [m]
Current input signal time = 133 [s]
Position at 2018-Dec-28 18:41:21 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1695.15 [m]
Current input signal time = 134 [s]
Position at 2018-Dec-28 18:41:21 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1701.38 [m]
Position at 2018-Dec-28 18:41:22 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1691.93 [m]
Current input signal time = 135 [s]
Position at 2018-Dec-28 18:41:22 UTC is Lat = 39.7941 [deg], Long = -105.153 [deg], Height= 1703.32 [m]
Position at 2018-Dec-28 18:41:23 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1682.33 [m]
Current input signal time = 136 [s]
Position at 2018-Dec-28 18:41:23 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1698.72 [m]
Once a position fix is achieved, the GNSS-SDR software generates NMEA sentences just like a conventional GPS receiver.
$GPRMC,184122.000,A,3947.6500,N,1059.2073,W,0.00,0.00,281218,,*2c
$GPGGA,184122.000,3947.6541,N,1059.2074,W,1,04,1.9,1690.0,M,0.0,M,0.0,0000*5d
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,40,31,61,178,45,32,55,047,41*7f
$GPRMC,184122.000,A,3947.6501,N,1059.2070,W,0.00,0.00,281218,,*2e
$GPGGA,184122.000,3947.6507,N,1059.2066,W,1,04,1.9,1691.9,M,0.0,M,0.0,0000*54
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,39,31,61,178,44,32,55,047,41*70
$GPRMC,184122.000,A,3947.6504,N,1059.2074,W,0.00,0.00,281218,,*2f
$GPGGA,184122.000,3947.6513,N,1059.2106,W,1,04,1.9,1679.1,M,0.0,M,0.0,0000*58
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,38,31,61,178,45,32,55,047,41*70
$GPRMC,184122.000,A,3947.6502,N,1059.2079,W,0.00,0.00,281218,,*24
$GPGGA,184122.000,3947.6466,N,1059.2070,W,1,04,1.9,1689.5,M,0.0,M,0.0,0000*50
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,41,31,61,178,45,32,55,047,43*7c
After sometimes waiting as long as twenty minutes for the SDR to acquire and track the minimum of four satellites necessary for a position fix and receiving the required navigational messages, I got the real-time report from gpstool
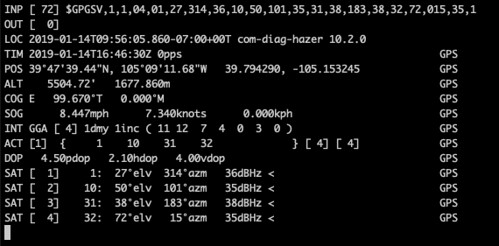
by piping the NMEA output into Hazer's gpstool
$ tail -f gnss_sdr_pvt.nmea | gpstool -E
which updated sporadically as the SDR had to acquire different satellites as they moved in their orbits. (You can tell from the timestamps that this was a different attempt from the one above.)
Below is a screen sweep of the commands I use to report all of the versions of the software and firmware.
# uname -a
Linux cadmium 4.15.0-43-generic #46~16.04.1-Ubuntu SMP Fri Dec 7 13:31:08 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.5 LTS
Release: 16.04
Codename: xenial
# gnuradio-config-info --version
3.7.13.4
# gnss-sdr --version
gnss-sdr version 0.0.10
# uhd_find_devices
[INFO] [UHD] linux; GNU C++ version 5.4.0 20160609; Boost_105800; UHD_3.14.0.0-0-gd20a7ae2
--------------------------------------------------
-- UHD Device 0
--------------------------------------------------
Device Address:
serial: 31736DE
name: MyB210
product: B210
type: b200
If, like me, you are interested in the finer details of how GPS works, this might be the setup for you. Just don't kid yourself. For just a few thousand dollars I am confident that you too can sometimes partially duplicate a fraction of the functionality and none of the reliability of a forty dollar USB dongle you can order from Amazon.com.
GPS chipset: SDR (USRP B210, GNURadio, GNSS-SDR)
Serial chipset: N/A
Serial parameters: N/A
udev Vendor/Product id: v2500p0020
Device name: N/A
Update frequency: sporadic
Such devices are not appropriate for the the kinds of precision timing applications I described in Engines of Time; my attempt to do so quickly revealed the latency and jitter that the serial-to-USB conversion introduces, and that is deadly to Network Time Protocol (NTP) applications. But GPS-over-USB devices are really useful for quickly cobbling together a geolocation application like I described in Better Never Than Late, or for determining the general time-of-day at least to the nearest second.
A quick search for "GPS USB" on Amazon.com reveals a pile of such devices (and lots of other stuff). Most are pretty inexpensive: a few tens of dollars, if that. This turned out to be really useful when I was working on Hazer, a simple little C library to parse NMEA GPS sentences. My tiny little company ended up buying a large assortment of these devices - ten in all, plus a few other more special purpose GPS devices that didn't have USB interfaces - allowing me to test Hazer against a broad range of of NMEA sentences. (There were a few surprises here and there.)
All of these devices emit ASCII data in a standard format described in the document NMEA 0183 Standard for Interfacing Marine Electronic Devices (version 4.10, NMEA 0183, National Marine Electronics Association, 2012-06). While NMEA charges a hefty fee (hundreds of dollars) for the document, summaries are available for the price of a little web search fu. Typical NMEA output looks like this.
$GPRMC,213605.000,A,3947.6533,N,10509.2018,W,0.01,136.40,150217,,,D*77\r\n $GPRMC,213605.000,A,3947.6533,N,10509.2018,W,0.01,136.40,150217,,,D*77\r\n $GPGGA,213606.000,3947.6533,N,10509.2018,W,2,10,1.0,1710.9,M,-20.8,M,3.0,0000*75\r\n $GPGGA,213606.000,3947.6533,N,10509.2018,W,2,10,1.0,1710.9,M,-20.8,M,3.0,0000*75\r\n $GPGSA,M,3,23,16,09,07,26,03,27,22,08,51,,,1.9,1.0,1.6*36\r\n $GPGSA,M,3,23,16,09,07,26,03,27,22,08,51,,,1.9,1.0,1.6*36\r\n $GPGSV,3,1,10,23,86,091,32,16,58,058,39,09,50,311,38,07,32,274,22*72\r\n $GPGSV,3,1,10,23,86,091,32,16,58,058,39,09,50,311,38,07,32,274,22*72\r\n $GPGSV,3,2,10,26,30,046,32,03,26,196,39,27,24,120,41,22,13,183,43*74\r\n $GPGSV,3,2,10,26,30,046,32,03,26,196,39,27,24,120,41,22,13,183,43*74\r\n $GPGSV,3,3,10,08,10,155,34,51,43,183,43*79\r\n $GPGSV,3,3,10,08,10,155,34,51,43,183,43*79\r\n
Because all the NMEA output is in ASCII, and the devices manifest as serial devices, you can play with them using your favorite terminal program, like screen for MacOS or Linux, or PuTTY on Windows.
Each sentence begins with a dollar sign and is terminated by an asterisk, with a simple checksum like 77, and carriage return/line feed pair. The NMEA application - GPS in this case, since there are other devices that emit other kinds of NMEA data - is identified with a GP, and its specific content by another token like, here, RMC, GGA, and GSV. Different sentences carrying different payloads, like the time of day in Universal Coordinated Time (UTC), current position in latitude and longitude expressed in degrees and decimal minutes, from exactly which satellites the position fix was derived, and the computed error in that position fix based on the orbital position of those satellites.
Why did I write Hazer to parse NMEA GPS sentences when there is plenty of perfectly usable open source code to do just that? In fact, I've used the most excellent open source GPS Daemon (gpsd) in all of my precision timing projects, as described in various articles like My WWVB Radio Clock. But as I'm fond of saying, I only learn by doing, and my goal with Hazer was to learn how NMEA GPS sentences were encoded. That turned out to be unexpectedly useful, as I've used what I've learned, and sometimes used Hazer itself, in a number of other projects, including one where I used gpsd as well.
All of the inexpensive GPS USB devices that I tested with Hazer use one of the following GPS chipsets.
- Quectel L80-R
- SiRF Star II
- SiRF Star III
- SiRF Star IV
- U-Blox 6
- U-Blox 7
- U-Blox 8
- Cygnal Integrated Products
- FTDI
- Prolific
- U-Blox (integrated into the GPS chip itself)
Most of these devices have an integrated patch antenna. As you will see in the photographs, a few required a separate amplified antenna in which the power was carried in-band over the coxial connection.
I didn't test the accuracy of any of these devices. But since they are all based on the a relatively small number of commercial GPS chipsets, a little web searching will yield useful information. All of these devices produced standard ASCII NMEA sentences that were easily usable by Hazer.
(Update 2019-11-25) I've tested all of the GPS/GNSS receivers shown in this article with my own software. The hosts used for testing vary widely depending on the application. They are all listed in the README for the Hazer repository.
Below is a list of the GPS USB devices, plus some others with other interfaces, that I used to test Hazer. For each, where possible, I identify the GPS chipset, the serial chipset, how often they generate an updated location, and some useful information regarding how to interface the device to a test system. If you are using any of these devices, or are trying to decide which to purchase, you may find this information useful.
This is an excellent unit for everyday general-purpose geolocation use. It is relatively inexpensive and easily available from a variety of outlets. This device's slower baud rate - 4800 baud - is actually an advantage for applications that integrate it with the real-time GPS feature of Google Maps Pro. (Updated 2018-08-27: the name of this company appears to have changed recently from USGlobalSat to GlobalSat.)
GPS chipset: SiRF Star IV
Serial chipset: Prolific
Serial parameters: 4800 8N1
udev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 1Hz
USGlobalSat ND-105C
Serial chipset: Prolific
Serial parameters: 4800 8N1
udev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 1Hz
USGlobalSat BU-353S4-5Hz
Like the other similar USGlobalSat unit but with a higher sentence frequency. (2018-08-27: the name of this company appears to have changed recently to from USGlobalSat to GlobalSat.)
Serial chipset: Prolific
Serial parameters: 115200 8N1
udev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 5Hz
Stratux Vk-162 Gmouse
Serial chipset: integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: v1546p01A7
Device name: ttyACM
Update frequency: 1Hz
Eleduino Gmouse
Serial chipset: integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: v1546p01A7
Device name: ttyACM
Update frequency: 1Hz
Generic Gmouse
(That is how it was listed on Amazon.com.)
Serial chipset: integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: v1546p01A7
Device name: ttyACM
Update frequency: 1Hz
Pharos GPS-360
Serial chipset: Prolific (likely integrated into provided cable)
Serial parameters: 4800 8N1
udev Vendor/Product id: v067BpAAA0
Device name: ttyUSB
Update frequency: 1Hz
Pharos GPS-500
GPS chipset: SiRF Star III
Serial chipset: Prolific (likely in provided dongle)
Serial parameters: 4800 8N1
udev Vendor/Product id: v067BpAAA0
Device name: ttyUSB
Update frequency: 1Hz
MakerFocus USB-Port-GPS
Shown attached to a Raspberry Pi as part of a larger project in which I integrated Hazer with Google Earth to create a moving map display. Supports 1PPS over a digital output pin.
GPS chipset: Quectel L80-R
Serial chipset: Cygnal (based on Vendor ID)
Serial parameters: 9600 8N1
udev Vendor/Product id: v10C4pEA60
Device name: ttyUSB
Update frequency: 1Hz
Sourcingbay GM1-86
GPS chipset: U-Blox 7
Serial chipset: probably integrated
Serial parameters: 9600 8N1
udev Vendor/Product id: p1546v01A7
Device name: ttyACM
Update frequency: 1Hz
Shown in a Raspberry Pi stack as part of Hourglass, a GPS-disciplined NTP server; it's the board with the SMA connector extending out the bottom to which a coaxial cable to an active antenna is attached.
Serial chipset: N/A (logic-level serial)
Serial parameters: 9600 8N1
udev Vendor/Product id: N/A
Device name: ttyAMA
Update frequency: 1Hz
Jackson Labs Technologies CSAC GPSDO
This is a breathtakingly expensive part, shown upper right as part of Astrolabe, an NTP server with a GPS-disciplined oscillator (GPSDO) that includes a cesium chip-scale atomic clock (CSAC).
Serial chipset: N/A (RS232 serial)
Serial parameters: 115200 8N1
udev Vendor/Product id: N/A
Device name: ttyACM
Update frequency: 1Hz
Garmin GLO
Purchased for and works well with Android GPS applications like the ones I routinely use with my Google Pixel C Android tablet.
Serial chipset: N/A (Bluetooth)
Serial parameters: N/A
udev Vendor/Product id: N/A
Device name: rfcomm
Update frequency: 10Hz
NaviSys Technology GR-701W (added 2018-05-04)
Supports a One Pulse Per Second (1PPS) signal by asserting DCD on the simulated serial port. Receives WAAS augmentation too. Can be used to build small GPS-disciplined NTP servers like Candleclock. The USB interface jitters the timing enough that it's my least precise NTP server, but it is still better than no local NTP server at all. It's available on Etsy.
GPS chipset: U-Blox 7
Serial chipset: Prolific
Serial parameters: 9600 8N1
dev Vendor/Product id: v067Bp2303
Device name: ttyUSB
Update frequency: 1Hz
TOPGNSS GN-803G (added 2018-08-08)
Has multiple RF stages so that it can receive more than one GNSS frequency at a time. Supports GPS, QZSS, GLONASS, and BEIDOU. By default, receives GPS and GLONASS and computes ensemble fixes. Supports WAAS, EGNOS, MSAS. Has seventy-two channels. A remarkable device for its price.
GPS chipset: U-Blox 8 (UBX-M8030-KT)
Serial chipset: U-Blox 8
Serial parameters: 9600 8N1
dev Vendor/Product id: v1546p01A8
Device name: ttyACM
Update frequency: 1Hz
GlobalSat BU-353W10 (added 2018-08-27)
Like the GN-803G above, this device uses the U-Blox 8 chipset, and so it has the multiple RF stages and computes ensemble fixes using GPS and GLONASS plus WAAS. It's a few dollars more than the GN-803G, but is available from Amazon.com with two-day shipping, where as I ordered the GN-803G from eBay and it was shipped from China. One interesting difference is that the GN-803G updates the satellite view (via NMEA GSV sentences) once per second, but the BU-353W10 updates the view every five seconds; the position fix and list of active satellite is still updated once a second. Since this device has advanced features I crave, and is easily acquired, it will likely be my go-to USB GPS device going forward (unless I need special features it doesn't have, like 1PPS).
GPS chipset: U-Blox 8 (UBX-M8030)
Serial chipset: U-Blox 8
Serial parameters: 9600 8N1
dev Vendor/Product id: v1546p01A8
Device name: ttyACM
Update frequency: 1Hz
Ardusimple SimpleRTK2B (updated 2019-02-24)
The SimpleRTK2B is an Arduino-compatible shield which can be used standalone, as I have done below, without headers through its USB-to-serial interface which also provides power. The SimpleRTK2B is based on the U-Blox ZED-F9P chip. This U-Blox 9 chip is remarkable in that it has all the goodness of the U-Blox 8, but also has the RF hardware and decode capability to receive not only GPS (U.S.) and GLONASS (Russia) signals, but also Galileo (E.U.) and Beidou (China). And it trivially does so, without any work on my part. Right out of the box, it computes an ensemble fix based on pseudo-ranges from all four constellations, and tries to use at least four satellites when possible from each constellation to do so. I suspect this makes it much more resistant to jamming and spoofing.
The device also supports Real-Time Kinematics (RTK), where two GPS receivers exchange information in the form of Radio Technical Commission for Maritime services (RTCM) messages, allowing built-in algorithms to potentially compute much more precise position fixes.
To receive signals from the four different constellations requires a multiband active antenna. The one I used is about the size of a hockey puck.
GPS chipset: U-Blox 9 (ZED-F9P)
Serial chipset: U-Blox 9
Serial parameters: 38400 8N1
dev Vendor/Product id: v1546p01A9
Device name: ttyACM
Update frequency: 1Hz
SparkFun GPS-RTK2 (updated 2019-07-12, 2019-11-25)
This is SparkFun's take on the same U-Blox 9 chip as is used in the Ardusimple SimpleRTK2B board. It lacks the Digi radio integration (which I ended up not using anyway). It has a USB-C port instead of a micro-B port. It provides a lithium battery to maintain memory on the receiver which might improve your chances of doing a hot start. Also, it ships from Boulder Colorado - a half hour or so drive from me - instead of from Barcelona Spain. So far it seems to function identically with Hazer, and its sister projects Yodel and Tumbleweed, as the SimpleRTK2B.
Below is a GPS-RTK2 board in an improvised case (a tiny 0.07 liter Really Useful Box from the office supply store; I've also used the 0.14 liter version), with a helical multi band active antenna. I used a Dremel tool to make holes for the USB connector, the antenna connector, and to mount the board to the bottom of the case using nylon standoffs. Side by side testing has shown the helical antenna to be less sensitive to weak signals than others I've used, but it is supposed to be less dependent on physical orientation (good for applications like drones).
Below is the GPS-RTK2 with the helical antenna in the window of my home office. Behind it is the hockey puck GNSS antenna mentioned above on a gimbaled camera mount with a steel ground plate (painted orange), and behind that, two marine GPS antennas. (When I took this photograph I had a total of eight GPS/GNSS antennas in my window, each connected to an active receiver.)
GPS chipset: U-Blox 9 (ZED-F9P)
Serial chipset: U-Blox 9
Serial parameters: 38400 8N1
dev Vendor/Product id: v1546p01A9
Device name: ttyACM
Update frequency: 1Hz
Software Defined Radio (updated 2019-02-05)
If you had any doubt as to the amazing capabilities of devices like the GlobalSat BU-353W10 GPS USB dongle described above - or any other consumer device that uses the Ublox 8 chipset - try duplicating it using a software defined radio (SDR) and open source software. My experience is I can get a small fraction of the performance of that US$40 device for about one hundred times its price and many
For sure your mileage may vary. My experience in this domain (which was hard won for me, not being a radio frequency guy, nor a signal processing guy, nor even a hardware guy) was that the performance of the GPS SDR depends on a bunch of environmental factors over which I have little or no control, like the weather (snowing == bad), or even time of day (sun == bad). After a long expensive learning experience, I am sometimes - but with no consistency or reliability - able to get a position fix. It is entirely possible that with more learning and less ignorance on my part, this setup could work a lot better. This is definitely a work in progress, although it is progressing very slowly.
Here's a photograph of my hardware.
After several false starts, I ended up using the Ettus Research B210 Universal Software Radio Peripheral (USRP). The B210 has a 12-bit analog to digital convertor - cheaper units use an 8-bit ADC - which I found was important for the SDR to be able to discriminate the GPS signals, which are so weak as to be barely detectable from the background radio noise. It has a USB 3.0 interface, which has been useful for the system to keep up with the fire hose of data from the B210. The B210 can be completely bus powered over the USB cable, which will be useful when I truck this around the neighborhood, as I am prone to do. I also opted to equip my B210 with an optional GPS-disciplined oscillator (GPSDO), that includes a temperature compensated crystal oscillator (TCXO), to use as a precision frequency source. That means I had to provide two GPS antennas, one for my GPS SDR, and one for the hardware GPS receiver. The irony of using a hardware GPS receiver to implement a software GPS receiver is not lost on me. The B210 is the cream colored box with the SMA connectors in the photograph above.
The B210 doesn't provide a bias tee (some radios do), a device that allows you to provide power over the coaxial cable to a GPS antenna that contains active elements in the form of a low noise amplifier. An LNA is necessary to boost the signals, which can be so weak as to be defeated just by the loss over the coax cable between the antenna and the radio. I tried several different bias tees (they aren't expensive, relatively speaking) before I settled on the little red device in the photograph, a CrysTek Microwave CBTEE-01-50-6000. I broke out my soldering iron to hand-fabricate the USB-to-SMA cable that powers the bias tee. (Update 2019-02-04: I've been trying other bias tees since then.)
The window of my home office now has eight GPS antennas sitting on the sill. Here are the two I used for my SDR.
I used two active 5V GPS antennas. I lovingly hand-crafted the dual setup (one for the SDR, one for the GPSDO) using two camera-tripod-style gimbaled mounts. Each mount has a ground plane, a conducting surface - here, a hunk of steel weighting about a quarter pound each - that has a radius of at least a quarter of a wavelength. The ground plane simulates the earth ground and serves to reflect the radio waves back into the antenna. I have no clue how necessary these are, but they were just a few bucks each.
The code name for this project is "Critter" and the repository containing the scripts and configuration files I used to implement it can be found on GitHub.
# gnss-sdr --config_file=../etc/gnss-b210-a.conf --log_dir=.
to run my GPS SDR, using a GNSS-SDR configuration file (update: whose name has since changed) that can be found in the repository for my project code-named Critter. Below is the output of one of my successful attempts.
NAV Message: received subframe 5 from satellite GPS PRN 31 (Block IIR-M)
NAV Message: received subframe 5 from satellite GPS PRN 32 (Block IIF)
NAV Message: received subframe 5 from satellite GPS PRN 10 (Block IIF)
Current input signal time = 125 [s]
Current input signal time = 126 [s]
Current input signal time = 127 [s]
Current input signal time = 128 [s]
Current input signal time = 129 [s]
Current input signal time = 130 [s]
NAV Message: received subframe 1 from satellite GPS PRN 31 (Block IIR-M)
NAV Message: received subframe 1 from satellite GPS PRN 32 (Block IIF)
NAV Message: received subframe 1 from satellite GPS PRN 18 (Block IIR)
NAV Message: received subframe 1 from satellite GPS PRN 10 (Block IIF)
Current input signal time = 131 [s]
First position fix at 2018-Dec-28 18:41:19 UTC is Lat = 39.7941 [deg], Long = -105.153 [deg], Height= 1713.42 [m]
The RINEX Navigation file header has been updated with UTC and IONO info.
Position at 2018-Dec-28 18:41:19 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1693.18 [m]
Current input signal time = 132 [s]
Position at 2018-Dec-28 18:41:19 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1704.55 [m]
Current input signal time = 133 [s]
Position at 2018-Dec-28 18:41:21 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1695.15 [m]
Current input signal time = 134 [s]
Position at 2018-Dec-28 18:41:21 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1701.38 [m]
Position at 2018-Dec-28 18:41:22 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1691.93 [m]
Current input signal time = 135 [s]
Position at 2018-Dec-28 18:41:22 UTC is Lat = 39.7941 [deg], Long = -105.153 [deg], Height= 1703.32 [m]
Position at 2018-Dec-28 18:41:23 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1682.33 [m]
Current input signal time = 136 [s]
Position at 2018-Dec-28 18:41:23 UTC is Lat = 39.7942 [deg], Long = -105.153 [deg], Height= 1698.72 [m]
Once a position fix is achieved, the GNSS-SDR software generates NMEA sentences just like a conventional GPS receiver.
$GPRMC,184122.000,A,3947.6500,N,1059.2073,W,0.00,0.00,281218,,*2c
$GPGGA,184122.000,3947.6541,N,1059.2074,W,1,04,1.9,1690.0,M,0.0,M,0.0,0000*5d
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,40,31,61,178,45,32,55,047,41*7f
$GPRMC,184122.000,A,3947.6501,N,1059.2070,W,0.00,0.00,281218,,*2e
$GPGGA,184122.000,3947.6507,N,1059.2066,W,1,04,1.9,1691.9,M,0.0,M,0.0,0000*54
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,39,31,61,178,44,32,55,047,41*70
$GPRMC,184122.000,A,3947.6504,N,1059.2074,W,0.00,0.00,281218,,*2f
$GPGGA,184122.000,3947.6513,N,1059.2106,W,1,04,1.9,1679.1,M,0.0,M,0.0,0000*58
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,38,31,61,178,45,32,55,047,41*70
$GPRMC,184122.000,A,3947.6502,N,1059.2079,W,0.00,0.00,281218,,*24
$GPGGA,184122.000,3947.6466,N,1059.2070,W,1,04,1.9,1689.5,M,0.0,M,0.0,0000*50
$GPGSA,M,3,10,18,31,32,,,,,,,,,5.0,1.9,4.6*3a
$GPGSV,1,1,04,10,33,120,42,18,46,253,41,31,61,178,45,32,55,047,43*7c
After sometimes waiting as long as twenty minutes for the SDR to acquire and track the minimum of four satellites necessary for a position fix and receiving the required navigational messages, I got the real-time report from gpstool
by piping the NMEA output into Hazer's gpstool
$ tail -f gnss_sdr_pvt.nmea | gpstool -E
which updated sporadically as the SDR had to acquire different satellites as they moved in their orbits. (You can tell from the timestamps that this was a different attempt from the one above.)
Below is a screen sweep of the commands I use to report all of the versions of the software and firmware.
# uname -a
Linux cadmium 4.15.0-43-generic #46~16.04.1-Ubuntu SMP Fri Dec 7 13:31:08 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.5 LTS
Release: 16.04
Codename: xenial
# gnuradio-config-info --version
3.7.13.4
# gnss-sdr --version
gnss-sdr version 0.0.10
# uhd_find_devices
[INFO] [UHD] linux; GNU C++ version 5.4.0 20160609; Boost_105800; UHD_3.14.0.0-0-gd20a7ae2
--------------------------------------------------
-- UHD Device 0
--------------------------------------------------
Device Address:
serial: 31736DE
name: MyB210
product: B210
type: b200
If, like me, you are interested in the finer details of how GPS works, this might be the setup for you. Just don't kid yourself. For just a few thousand dollars I am confident that you too can sometimes partially duplicate a fraction of the functionality and none of the reliability of a forty dollar USB dongle you can order from Amazon.com.
GPS chipset: SDR (USRP B210, GNURadio, GNSS-SDR)
Serial chipset: N/A
Serial parameters: N/A
udev Vendor/Product id: v2500p0020
Device name: N/A
Update frequency: sporadic
Thursday, April 19, 2018
Frames of Reference II
I'm taking an weekly adult education class at University of Denver on the science and nature of time. Me, an adult, if you can imagine it, but perhaps not so surprising a topic for a guy that has his own cesium atomic clock and several Swiss mechanical wristwatches. The instructor, a semi-retired astronomer that worked on the Hubble space telescope, had us do an interesting experiment the other evening.
Take off your shoe and mindfully touch your big toe with your index finger. The sensations you experience are traveling along three different paths:
Here's the thing: there is about a 80 millisecond difference in delay between the latency from your eyes and the latency from your toe, with your finger falling in between. 80ms is nearly a tenth of a second. That's easily perceptible by the human brain; we recognize 1/10s delay routinely when listening to music. I own a mechanical watch - a vintage Eterna-Matic 36000 - that audibly ticks at 10Hz or 10 times a second.

But this difference in latency isn't apparent when we do this little experiment. Why not? There are some shenanigans going on in our brain regarding the processing of those sensations and it affects our perception of time.
Googling for this topic reveals all sorts of interesting research, the most common result being "hearing is faster than seeing", in part because of the processing involved. A lot of the research is done to determine how fast is fast enough to seem "instantaneous" and is motivated by response time studies. In the more recent decades, the computer gaming industry has been doing this kind of research.
But I was struck at the eerie similarities between this vagary of human perception and the how design and implementation decisions could affect latencies and therefore the ordering of events in real-time systems that I wrote about in this blog in Frames of Reference just a month earlier.
Take off your shoe and mindfully touch your big toe with your index finger. The sensations you experience are traveling along three different paths:
- the light reaches your eyes, then the visual cue travels a very short distance to your brain through your nervous system;
- the sensation of your finger touching your toe travels through your nervous system, up your arm to your spinal cord, then a short distance to your brain;
- the sensation of your toe touching your finger travels a relatively long distance up your leg, up your spinal cord, to your brain.
Here's the thing: there is about a 80 millisecond difference in delay between the latency from your eyes and the latency from your toe, with your finger falling in between. 80ms is nearly a tenth of a second. That's easily perceptible by the human brain; we recognize 1/10s delay routinely when listening to music. I own a mechanical watch - a vintage Eterna-Matic 36000 - that audibly ticks at 10Hz or 10 times a second.
But this difference in latency isn't apparent when we do this little experiment. Why not? There are some shenanigans going on in our brain regarding the processing of those sensations and it affects our perception of time.
Googling for this topic reveals all sorts of interesting research, the most common result being "hearing is faster than seeing", in part because of the processing involved. A lot of the research is done to determine how fast is fast enough to seem "instantaneous" and is motivated by response time studies. In the more recent decades, the computer gaming industry has been doing this kind of research.
But I was struck at the eerie similarities between this vagary of human perception and the how design and implementation decisions could affect latencies and therefore the ordering of events in real-time systems that I wrote about in this blog in Frames of Reference just a month earlier.
Wednesday, April 18, 2018
renameat2(2)
I just recently discovered that Linux kernels from about version 3.15 or so implement a system call called renameat2. (That's pronounced "rename at 2" not "rena meat 2" BTW.) This is a useful thing to know, because a close reading of the renameat2(2) manual page reveals it eliminates two related thorny problems that I haven't found any other way to solve.
I also discovered that despite what the output of the man renameat2 command might imply about the C function prototype, recent versions of the glibc library, at least the one on my Ubuntu 16.04 "xenial" development system, don't provide a function wrapper for the system call. Fortunately, it turns out that you can easily roll your own, something I have never had to do before.
Here is the implementation of the equivalent C function.
(N.B. In these code snippets I've eliminated all the error checking for clarity. In my production code, I am avidly paranoid about checking all error returns. I encourage you to do the same. All of these code snippets are from actual running examples. Since Blogger seems incapable of consistently displaying my code snippets correctly across all browsers - they all look correct in the Blogger editor - these snippets can be found on GitHub.)
A careful application of strace(1) on some unit tests reveals nothing but goodness in the result.
Problem One
Accidents happen. Mistakes are made. No matter how carefully you write your boot-time start-up scripts, or your interactive restart scripts, for system daemons, sooner or later your product is going to try to start the same daemon twice. This will happen in the development lab, or during quality assurance testing, if no where else. Wackiness may ensue.
A common idiom used to prevent this is for a daemon to initially create a lock file with a unique name like /run/lock/mydaemonname.lck in such a way that if the file already exists, the file creation fails, and the daemon exits assuming that prior version of itself is already running. This lock file is deleted when the daemon exits, and the entire /run/lock directory is cleaned up when the system reboots.
Ensuring that the lock file does not already exist can be easily done by using the combination of the O_CREAT | O_EXCL | O_WRONLY flags on on the open(2) system call; the system call will fail if the file already exists, and the check for it existing, and the subsequent creation of the file, is atomic. There is no way another process running concurrently on the system can see an intermediate result. The Linux kernel and its file system implementation guarantees that the file either exists, or it doesn't exist; there is no possible race condition.
This pattern gets ugly when the daemon wants to implement another commonly used idiom: writing its own process identifier, typically as text, into the lock file. This is really useful, because it allows other applications to verify that the daemon that created the lock file is still running, and to subsequently communicate with it, for example by sending it a signal. The ugliness happens because if the daemon atomically creates the file using open(2), then writes its PID into the file, applications can easily see an intermediate state: an empty lock file, or worse, a lock file with only a partially written PID that may look legitimate, because writing the PID to the lock file isn't necessarily atomic.
What the daemon would like to do is create a unique temporary file, perhaps using mkstemp(3), write its PID into that file, then atomically rename(2) the temporary file to the name of the lock file using the same exclusivity semantics as provided by open(2). We want the lock file to have exactly two visible states:
Here is the implementation of the lock function.
Problem Two
Another common idiom is for a parent process to atomically create an empty lock file, fork(2) off a child process, the child process daemonifies itself, then it writes its PID into the lock file. In this approach, the lock file has three states instead of two:
The initial atomic creation of the lock file can be done as described previously using open(2) with the appropriate flags. As a subsequent step, the child process creates a temporary file containing its PID, and, providing the temporary file and the lock file are in the same file system, renameat2(2) can be used with its RENAME_EXCHANGE flag to atomically swap the temporary file and the lock file. renameat2(2) does all the heavy lifting for us by not only atomically swapping the two files, but also by guaranteeing that the two files are in the same file system, and insuring that the lock file already exists.
Here is the implementation of the pre-lock function called by the parent process that atomically exclusively creates the lock file, and the post-lock function called by the child that populates the lock file with the child's PID. (The implementation of the functions to delete the lock file, and to read the PID from the lock file, are left as an exercise for the reader.)
Note that once the swap is successful, the post-lock function deletes the temporary file, which will now be empty.
Alternatives
I recently worked on a embedded product development project in which the underlying Linux distribution chosen by the team supported systemd(1), the system and service manager. systemd replaces the bulk of the boot-time init infrastructure, daemon start-up scripts, and even the cron daemon. As you might imagine, its introduction is somewhat controversial in the Linux mainstream, especially given that the traditional UNIX architectural philosophy is to resist centralized management.
But I - who have been doing embedded Linux development since the Linux 2.4 kernel - was a little surprised to find I liked systemd. If your projects supports systemd, you will find that it provides other mechanisms to manage the daemons you might be called upon to write. You should use those mechanisms.
My computer scientist friends will have appreciated that the renameat2 system call implements a kind of semaphore or mutex, or at least a kind of atomic swap that can be used to implement such capabilities, in the file system. That means there are probably lots of other things it can be used for.
Final Remarks
I like renameat2(2) because I haven't found any other way to reliably and simply implement what it provides. In fact, renameat2(2) is so uniquely useful, I suspect that systemd(1) uses the renameat2 system call under the hood to perform its own service management. (Update: I just checked the systemd repository on GitHub and this is indeed the case.)
I came to use renameat2(2) in the implementation of the diminuto_lock.c feature, and in the renametool utility, in my Diminuto C-based systems programming library. Diminuto is a collection of useful C functions and utilities I have written that has found its way into a number of shipping products, not to mention in many of my internal projects.
I also discovered that despite what the output of the man renameat2 command might imply about the C function prototype, recent versions of the glibc library, at least the one on my Ubuntu 16.04 "xenial" development system, don't provide a function wrapper for the system call. Fortunately, it turns out that you can easily roll your own, something I have never had to do before.
Here is the implementation of the equivalent C function.
(N.B. In these code snippets I've eliminated all the error checking for clarity. In my production code, I am avidly paranoid about checking all error returns. I encourage you to do the same. All of these code snippets are from actual running examples. Since Blogger seems incapable of consistently displaying my code snippets correctly across all browsers - they all look correct in the Blogger editor - these snippets can be found on GitHub.)
#include <stdio.h> #include <fcntl.h> #define _GNU_SOURCE #include <unistd.h> #include <sys/syscall.h> int renameat2(int olddirfd, const char * oldpath, int newdirfd, const char * newpath, unsigned int flags) { return syscall(SYS_renameat2, olddirfd, oldpath, newdirfd, newpath, flags); }
A careful application of strace(1) on some unit tests reveals nothing but goodness in the result.
Problem One
Accidents happen. Mistakes are made. No matter how carefully you write your boot-time start-up scripts, or your interactive restart scripts, for system daemons, sooner or later your product is going to try to start the same daemon twice. This will happen in the development lab, or during quality assurance testing, if no where else. Wackiness may ensue.
A common idiom used to prevent this is for a daemon to initially create a lock file with a unique name like /run/lock/mydaemonname.lck in such a way that if the file already exists, the file creation fails, and the daemon exits assuming that prior version of itself is already running. This lock file is deleted when the daemon exits, and the entire /run/lock directory is cleaned up when the system reboots.
Ensuring that the lock file does not already exist can be easily done by using the combination of the O_CREAT | O_EXCL | O_WRONLY flags on on the open(2) system call; the system call will fail if the file already exists, and the check for it existing, and the subsequent creation of the file, is atomic. There is no way another process running concurrently on the system can see an intermediate result. The Linux kernel and its file system implementation guarantees that the file either exists, or it doesn't exist; there is no possible race condition.
This pattern gets ugly when the daemon wants to implement another commonly used idiom: writing its own process identifier, typically as text, into the lock file. This is really useful, because it allows other applications to verify that the daemon that created the lock file is still running, and to subsequently communicate with it, for example by sending it a signal. The ugliness happens because if the daemon atomically creates the file using open(2), then writes its PID into the file, applications can easily see an intermediate state: an empty lock file, or worse, a lock file with only a partially written PID that may look legitimate, because writing the PID to the lock file isn't necessarily atomic.
What the daemon would like to do is create a unique temporary file, perhaps using mkstemp(3), write its PID into that file, then atomically rename(2) the temporary file to the name of the lock file using the same exclusivity semantics as provided by open(2). We want the lock file to have exactly two visible states:
- the lock file does not exist;
- the lock file exists and contains a valid process identifier.
Here is the implementation of the lock function.
int my_lock(const char * file) { static const char SUFFIX[] = "-lock-XXXXXX"; pid_t pid = getpid(); char * path = (char *)malloc(strlen(file) + sizeof(SUFFIX)); strcpy(path, file); strcat(path, SUFFIX); int fd = mkstemp(path); FILE * fp = fdopen(fd, "w"); fprintf(fp, "%d\n", pid); fclose(fp); int rc = renameat2(AT_FDCWD, path, AT_FDCWD, file, RENAME_NOREPLACE); if (rc < 0) { unlink(path); } free(path); return rc; }
Problem Two
Another common idiom is for a parent process to atomically create an empty lock file, fork(2) off a child process, the child process daemonifies itself, then it writes its PID into the lock file. In this approach, the lock file has three states instead of two:
- the lock file does not exist,
- the lock file exists but is empty,
- the lock file exists and contains a valid PID.
The initial atomic creation of the lock file can be done as described previously using open(2) with the appropriate flags. As a subsequent step, the child process creates a temporary file containing its PID, and, providing the temporary file and the lock file are in the same file system, renameat2(2) can be used with its RENAME_EXCHANGE flag to atomically swap the temporary file and the lock file. renameat2(2) does all the heavy lifting for us by not only atomically swapping the two files, but also by guaranteeing that the two files are in the same file system, and insuring that the lock file already exists.
Here is the implementation of the pre-lock function called by the parent process that atomically exclusively creates the lock file, and the post-lock function called by the child that populates the lock file with the child's PID. (The implementation of the functions to delete the lock file, and to read the PID from the lock file, are left as an exercise for the reader.)
int my_prelock(const char * file) { int fd = open(file, O_CREAT | O_EXCL | O_WRONLY, 0600); if (fd < 0) { return -1; } close(fd); return 0; } int my_postlock(const char * file) { static const char SUFFIX[] = "-post-XXXXXX"; pid_t pid = getpid(); char * path = (char *)malloc(strlen(file) + sizeof(SUFFIX)); strcpy(path, file); strcat(path, SUFFIX); int fd = mkstemp(path); FILE * fp = fdopen(fd, "w"); fprintf(fp, "%d\n", pid); fclose(fp); int rc = renameat2(AT_FDCWD, path, AT_FDCWD, file, RENAME_EXCHANGE); unlink(path); free(path); return rc; }
Note that once the swap is successful, the post-lock function deletes the temporary file, which will now be empty.
Alternatives
I recently worked on a embedded product development project in which the underlying Linux distribution chosen by the team supported systemd(1), the system and service manager. systemd replaces the bulk of the boot-time init infrastructure, daemon start-up scripts, and even the cron daemon. As you might imagine, its introduction is somewhat controversial in the Linux mainstream, especially given that the traditional UNIX architectural philosophy is to resist centralized management.
But I - who have been doing embedded Linux development since the Linux 2.4 kernel - was a little surprised to find I liked systemd. If your projects supports systemd, you will find that it provides other mechanisms to manage the daemons you might be called upon to write. You should use those mechanisms.
My computer scientist friends will have appreciated that the renameat2 system call implements a kind of semaphore or mutex, or at least a kind of atomic swap that can be used to implement such capabilities, in the file system. That means there are probably lots of other things it can be used for.
Linux (and other UNIX variants) provide other synchronization and mutual-exclusion mechanisms through which something like this could be implemented. But this approach just uses the file system. It requires only a small amount of cooperation between the applications that make use of it. It's simple and straight forward.
Important Safety Tips
renameat2(2) requires support from the underlying file system. Not all file systems may implement it. Some, especially network file systems, may never be able to implement it, because of their semantics.
At least on Ubuntu 16.04 "xenial", the synthetic processor implemented by valgrind(1) doesn't provide the renameat2 system call. This means you can't test applications using that call for memory leaks. This makes me nervous.
Important Safety Tips
renameat2(2) requires support from the underlying file system. Not all file systems may implement it. Some, especially network file systems, may never be able to implement it, because of their semantics.
At least on Ubuntu 16.04 "xenial", the synthetic processor implemented by valgrind(1) doesn't provide the renameat2 system call. This means you can't test applications using that call for memory leaks. This makes me nervous.
I like renameat2(2) because I haven't found any other way to reliably and simply implement what it provides. In fact, renameat2(2) is so uniquely useful, I suspect that systemd(1) uses the renameat2 system call under the hood to perform its own service management. (Update: I just checked the systemd repository on GitHub and this is indeed the case.)
I came to use renameat2(2) in the implementation of the diminuto_lock.c feature, and in the renametool utility, in my Diminuto C-based systems programming library. Diminuto is a collection of useful C functions and utilities I have written that has found its way into a number of shipping products, not to mention in many of my internal projects.
Subscribe to:
Posts (Atom)

