And so it came to pass that I needed a solution to the Reader-Writer Problem using POSIX threads and written in C. So that there would be a consistent perception of reality amongst the components of a real-time system, it would be required that the Readers and Writers be given access to the shared resource in the strict order in which their requests were made. So it was, in the fullness of time, I developed such a solution. And I found it was good.
The Reader-Writer Problem
The Reader-Writer Problem (or, sometimes, the Readers-Writers Problem) is a classic concurrency problem in computer science. I studied it in school in the 1980s, but papers were being published about it in the early 1970s, just as computers were large enough to actually run more than one program at a time, and shared databases were becoming commonplace.
A Reader is any algorithm that needs read-only access to a shared resource. That shared resources could be a persistent database, a complex data structure in memory, or just a variable. A Writer is any algorithm that needs read-write access to the same shared resource. The Reader-Writer Problem is all about how you keep Writers from stepping on each other and on Readers as they modify the shared data.
The classic example of this in all the introductory textbooks is your bank balance. An algorithm in the bank computer, Writer A, wants to see if you have enough money in your bank account to cover your ATM withdrawal of $200. It reads your balance, and sees that you have a balance of $500, and tells the ATM to give you your money. Meanwhile, Writer B want to see if you have enough money to cover a check for $400 drawn against your account. It reads your balance, sees that you do, and clears the check. Writer A deducts the $200 from your account. Writer B deducts the $400 from your account... and now you see the problem.
(The thing is: this actually happens all the time. The global banking system is distributed across a huge number of computers, and verifying every single transaction in real-time is too expensive and time consuming. The banking system reconciles all of the transactions at best at the end of the day. So sometimes you overdraw your account. But it works as an introductory example.)
So clearly the act of checking your balance and deducting the money needs to be done as an atomic, or indivisible, operation - without the balance being changed in the middle of the transaction. Hence, only one Writer can run at a time.
If all an algorithm is doing is reading - a Reader that just checks your bank balance - that is an operation that can be done concurrently with other read-only operations. Readers don't step on one another, and many Readers can run at the same time. For reasons of efficiency, there is no reason to block a Reader if only other Readers are running.
A Writer can step on a Reader, too. Perhaps a Reader accesses a shared account database to verify two separate things: that the password that was typed in matches the (probably encrypted) password in the database, and that the login entered has access to the specific resources that the user is trying to use. Both requirements must be met for the login to succeed, but the data that needs to be verified must be accessed in two different read operations. In between those two separate operations, a Writer steps in and processes a Change Password request. The result is that the Reader grants access, even though the password typed in was actually incorrect at the time access was granted.
(That probably happens all the time, too.)
So while multiple Readers can access a shared resource concurrently, Writer access must be serialized - only one Writer can access it at a time - and Readers have to wait until a Writer has completed and vice versa. Note how this is different than just placing each access of the resource, regardless of read-write semantics, inside a critical section protected by a mutex or a semaphore: that would unnecessarily serialize Readers' access as well as that of Writers. If most access is reading - which typically is the case - a Reader-Writer lock is far more efficient than a simple mutex.
Those are the basic rules, or invariants, for the Reader-Writer Problem. But typical solutions to the Reader-Writer Problem are more complicated than that. For example, if you have a constant stream of Readers, the simplest solution to the Reader-Writer Problem starves Writers; they are constantly blocked from modifying the shared resource as long as Readers keep requesting access, because the simplest solution gives Readers priority.
This doesn't really serve Readers either, since presumably a Reader wants the most up-to-date information in the database. Starving Writers really means that the data is old and effectively out of date with respect to the real-world - you have written a lot of checks that have not yet cleared, so your bank balance reflects what an accountant would call its cash basis, not its accrual basis. That makes the data the Readers are reading a lot less practically useful.
Likewise, giving Writers priority can starve Readers if there is a constant stream of Writers wanting to modify the shared resource. That's not useful either, since you have a database with a lot of up-to-date information that Readers cannot access.
So you have to have a balance. The devil is in the details, which is why there are a lot of different solutions to the Reader-Writer Problem, all maintaining the same basic invariants regarding the integrity of the shared resource, but with different scheduling and policy decisions for Readers and Writers. Each solution is designed to meet the requirements of some specific application, or exhibit some specific behavior, like Readers are given priority as long as Writers don't wait longer than some timeout period, establishing a kind of "best if used before" date on the shared data.
And so we come to the requirements for my solution.
My Reader-Writer Problem
I had some specific needs for my solution. Not only did I need to meet the basic invariants of the Reader-Writer Problem, I needed the requests by Readers and Writers to be performed in the time order in which they occurred. Readers can run concurrently, but as soon as a Writer waits for the Readers to complete, all further Readers have to wait. More importantly (and the thing that was the departure from many Reader-Writer solutions), subsequent Readers and Writers that wait must be granted access to the shared resource in the order in which they made their request.
For example, if the order of arrival of Readers (R) and Writers (W) were in the following time ordered sequence (from left to right)
R1 R2 R3 R4 W1 W2 R5 R6 W3 R7 W4 R8
- R1, R2, and R3 would all immediately be granted concurrent access;
- then W1;
- then W2;
- then R5 and R6 could run at the same time;
- then W3;
- then R7;
- then W4;
- then finally R8.
Other Reader-Writer algorithms may exhibit higher throughput for Readers, or for Writers, but this approach provides a more consist view of "causality", so that a post-hoc analysis of real-time system behavior agrees with the accepted perception of the order of events. I say "more consistent" and "accepted order" because a perfectly consistent view is impossible. I've written about this in my "Frame of Reference" blog articles, essentially applying Einstein's Theory of Special Relativity to real-time systems. (Computer scientist Leslie Lamport beat me to this idea by more than forty years.)
My Reader-Writer Solution
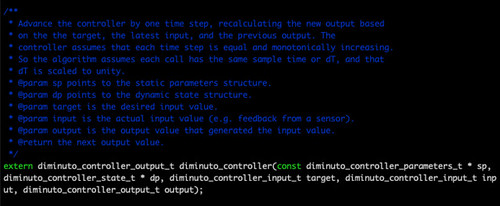
My solution is implemented in C under Linux using the GNU C library's implementation of POSIX threads, mutexen, and condition variables (and is different in implementation and probably behavior from the pthread_rwlock_t that POSIX provides - POSIX isn't that clear about how it behaves). You can find the source code in my Diminuto C systems programming library, whose Git repository is hosted on GitHub. Or you can follow the links below just to take a quick look at it right now.
The POSIX mutex and condition variable features together implement a form of synchronization originally referred to as a "monitor", as distinct from the earlier synchronization primitive, the "semaphore". Specifically, POSIX implements a Mesa monitor, whose behavior matches that of the monitors implemented in the Mesa programming language developed at Xerox PARC in the 1980s. Mesa monitors differ somewhat from the behavior of the original monitors described by C. A. R. Hoare several years earlier. I won't describe the POSIX mutexen or condition variables in detail, or either Mesa or Hoare monitors, but the references can be found below.
The one detail I do need to point out is that POSIX condition variables - a kind of queue on which threads can wait until another thread signals them to resume execution - do not guarantee First-In First-Out (FIFO) order: the order in which threads awaken on a condition variable can be completely different from the order in which they originally waited. POSIX condition variables are not guaranteed to be first come, first served. The order may be be affected by the scheduling priority that the application assigns to each thread, or it may depend on some specific detail of the underlying implementation. In any case, it is undefined in the POSIX 1003.1 specification. That was a problem I had to solve.
(There has been so much published on the Reader-Writer Problem over the decades that I would never claim that this solution is novel. It has undoubtedly been done before, and probably better. But a working implementation in the hand is worth two articles in the unread academic literature.)
(Update 2021-01-04: I found another, earlier, and very different implementation, by Shlomi Fish, which I added to the references at the end.)
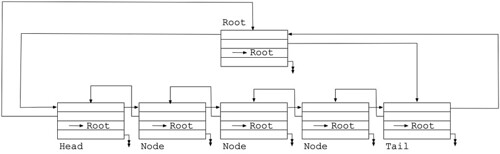
My solution uses one POSIX mutex, two POSIX condition variables (reader and writer), two counters that track the number of active Readers and Writers (reading, which should always be zero or greater, and writing, which should always be zero or one), and a queue used to store tokens (ring, which I implement as a ring or circular buffer).
(Update 2022-01-27: Diminuto library versions 74 and later do not require that the application provide storage for a ring buffer. The ring buffer is replaced by a diminuto_list_t, a doubly-linked "wait list", that is provisioned automatically and managed internally. The parameters to diminuto_readerwriter_init that provide a pointer to the ring buffer and its size have been eliminated. All other details remain the same.)
Once the Reader-Writer lock has been initialized, there are only four basic operations: a Reader can request access, a Reader can relinquish access, a Writer can request access, and a Writer can relinquish access.
Reader Request
When a Reader requests access and there are no active Writers (writing is zero) and there are no tokens on the ring, the reading counter is incremented and the Reader is granted access.
When a Reader requests access and there is an active Writer (writing is one), or if there are tokens on the ring, the Reader appends a READER token (indicating a waiting Reader) to the tail of the ring and waits on the reader condition variable.
When a waiting Reader wakes up, it checks to see if its token is at the head of the ring, and that it has been changed to READING (indicating a ready Reader). If both are true, it removes its token from the head of the ring, and proceeds to access the shared resource. (As we shall soon see, the reading counter will have already been incremented. This is important so that newly arriving Readers or Writers will not see the reading or writing counters as zero before the awakened thread has had time to reacquire the mutex.) If not, it waits again on the reader condition variable.
Just before a Reader exits the critical section that surrounds the Reader request mechanism, it checks to see if there is waiting Reader as the head of the ring. If there is, the exiting Reader changes the token at the head of the ring from READER to READING, increments the reading counter, and broadcasts a signal that wakes up all of the Readers on the reader condition variable. We have to use the broadcast POSIX function - which wakes all waiting threads - instead of the signal POSIX function - which wakes one waiting thread - because we don't know in what order threads will be awakened by POSIX, since FIFO order is not guaranteed.
Reader Relinquish
When the Reader relinquishes the shared resource, it first decrements the reading counter. If the reading counter is not zero, it is done. If the reading counter is zero (indicating there no other concurrent Readers), the relinquishing Reader checks to see if there is a waiting Reader or a waiting Writer by looking for a token at the head of the ring.
If there is a waiting Reader, the relinquishing Reader changes the token at the head of the ring from READER to READING, increments the reading counter, and broadcasts a signal that wakes up all of the waiting Readers on the reader condition variable.
Similarly, if there is a waiting Writer, the relinquishing Reader changes the token at the head of the ring from WRITER to WRITING, increments the writing counter, and broadcasts a signal that wakes up all of the waiting Writers on the writer condition variable.
Writer Request
When a Writer requests access and there are no active Readers or Writers (both reading and writing are zero) and there are no tokens on the ring, the writing counter is incremented and the Writer is granted access.
When a Writer requests access and there are one or more active Readers, or an active Writer, or there are tokens on the ring , the Writer appends a WRITER token to the ring and waits on the writer condition variable.
When a waiting Writer wakes up, it checks to see if its token is at the head of the ring and that it has been changed to WRITING. If both are true, it removes its token from the head of the ring, and proceeds to access the shared resource. If not, it waits again on the writer condition variable.
Writer Relinquish
When the Writer relinquishes the shared resource, it first decrements the writing counter. It then checks to see if there is a waiting Reader or a waiting Writer by looking for a token at the head of the ring.
If there is a waiting Reader, the relinquishing Writer changes the token at the head of the ring from READER to READING, increments the reading counter, and broadcasts a signal that wakes up all of the waiting Readers on the reader condition variable.
Similarly, if there is a waiting Writer, the relinquishing Writer changes the token at the head of the ring from WRITER to WRITING, increments the writing counter, and broadcasts a signal that wakes up all of the waiting Writers on the writer condition variable.
Practical Matters
The variables for the Reader-Writer lock are baked into a structure that has its own type definition.
diminuto_readerwriter_t lock;
The structure contains the mutex, the two condition variables, the counters, and the metadata for the ring buffer; the actual storage for the ring buffer is provided by the application in the form of an array that is at least as large as the maximum number of threads that may use the lock at any one time. Each slot in the array is just one byte. No initialization of the array is necessary. (My implementation doesn't have to do any initialization of the array either; the ring buffer metadata insures that the implementation never examines an uninitialized slot in the array.)
(Update 2022-02-01: In addition to the initialization function shown below, Diminuto library versions 74 and above also provide a mechanism for static initialization of the ReaderWriter lock structure. This allows the structure to be automatically initialized by the C run-time static initialization when an application starts.)
There is a function that initializes the ReaderWriter lock structure.
uint8_t ring[64];
diminuto_readerwriter_init(&lock, ring, 64);
Using the Reader-Writer lock is probably the simplest part, since all the necessary code is generated by C preprocessor macros that implement a "bracketing" pattern. These let you use the Reader-Writer lock like this, for Readers:
DIMINUTO_READER_BEGIN(&lock);/* Read the shared resource here. */
DIMINUTO_READER_END;
or like this, for Writers:
DIMINUTO_WRITER_BEGIN(&lock);
/* Read and write the shared resource here. */
DIMINUTO_WRITER_END;
If one of the underlying POSIX functions fails for some reason (the most likely reason for this is the developer forgot to initialize the lock structure), the section of code bracketed by the macros is not executed. There is no error indication to the application, but it is a simple thing for the application to check that the code was executed. The implementation logs error messages either to standard error, or to the system log if the application has no controlling terminal i.e. is a daemon, so failures are not silent.
Discussion
Why two condition variables, one for Readers, and another for Writers?
Although I haven't tested it, my algorithm should work just fine having all of the waiting threads queued on a single condition variable. The waiting Readers and Writers don't depend on what condition variable they wake up on to know whether they've been granted access to the shared resource. There could be one token indicating READY that the head of the ring is set to, whether from a READER or from a WRITER, instead of the two different ready tokens, READING or WRITING. I think the only difference would be more churn amongst signaled Readers and Writers until all but one thread, the one whose token is at the head of the ring, go back to waiting.
Another approach would be to make every slot in the ring a condition variable. Each waiting thread would wait on its own dedicated condition variable. The signaling thread could signal instead of broadcast, since there would be no ambiguity as to which thread was being woken up. My only concern about this would be the resource usage involved.
I'm not unhappy about my design, so I'm not likely to change it. Using two condition variables seems efficient enough, and using a condition variable per slot in the ring doesn't seem necessary.
My design orders the access to the shared resource independently of the priorities of the calling threads, so it can result in priority inversion (but to not to do so would violate my own requirements).
One of the capabilities I have thought about adding is an optional timeout on the request for Readers and Writers, using a POSIX timed wait. I'm not completely convinced that there is a use case for this, except perhaps when recovering from some failure; how many algorithms have a credible Plan B if the request for the lock times out? It would also require that tokens in the middle of the ring be capable of being be rescinded. This is a lot harder than it sounds. Either the ring needs to be converted into something like a Diminuto List, a circular doubly-linked list (which would greatly increase the size of each slot from one byte to four pointers); or the maximum size of the ring can no longer be calculated (a Reader or Writer may timeout many times, each time adding a token to the tail while leaving an old token on the ring waiting to be removed at the head). I'm still pondering this.
(Update 2021-01-07: And I ultimately implemented the timeout, in part because it made it easier to test the recovery from certain failure scenarios. The timeout is available in the public function API, but not in the wrapper macros. You can find examples of both uses in the unit test. A timeout duration of zero provides a way for the application to poll for the availability of the resource.)
(Update 2022-01-30: As mentioned above, I finally replaced the ring buffer with a Diminuto List. The List node for each thread is automatically dynamically allocated in the thread's local storage and initialized on its first use. It is automatically de-initialized and freed when the thread exits.)
(Update 2022-01-30: Diminuto library versions 75 and above support an expedited access request which queues the requesting thread at the head of the wait list instead of at the end. This provides a broad variety of alternatives in terms of how threads are scheduled to use the resource.)
My Diminuto library and the results of its Reader-Writer solution should be pretty easy to reproduce on any modern Linux/GNU system. If this is the kind of thing that overclocks your processor, try it out. Clone the repository. Build the code base. Run the unit test. Peruse the code. See what you think. The unit test has passed on an x86_64 Ubuntu 18.04 platform, and on an ARMv8 Raspian 10 platform.
(Update: I made minor edits, and additions to the Discussion section, since I first posted this.)
For Further Reading
Wikipedia, "Readers-writers problem", 2020-11-23
Wikipedia, "Readers-writer lock", 2020-11-16
C. Overclock, "Frames of Reference IV", 2020-05-22
C. Overclock, "Frames of Reference III", 2020-01-28
C. Overclock, "Frames of Reference II", 2018-04-19
C. Overclock, "Frames of Reference", 2018-03-14
pthread_cond_timedwait, pthead_cond_wait, Open Group Base Specification Issue 7, 2018 edition, IEEE Std. 1003.1-2017, 2018
pthread_cond_broadcast, pthead_cond_signal, Open Group Base Specification Issue 7, 2018 edition, IEEE Std. 1003.1-2017, 2018
S. Fish, "A First-Come First-Served Readers/Writers Lock", 2009-04-18
B. Lampson, D. Redell, "Experience with Processes and Monitors in Mesa", Communications of the ACM, 23.2, 1980-02
L. Lamport, "Time, Clocks, and the Ordering of Events in a Distributed System", Communications of the ACM, 21.7, 1978-07
C. Hoare, "Monitors: An Operating System Structuring Concept", Communications of the ACM, 17.10, 1974-10
P. Courtois, F. Heymans, D. Parnas, "Concurrent Control with ''Readers'' and ''Writers''", Communications of the ACM, 14.10, 1971-10