(Click on any image to see a larger version. Or any version of all, since Blogger doesn't alway play well with Flickr.)
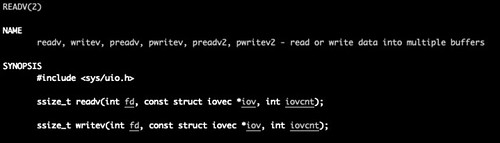
These calls take, not a pointer to a buffer and a length in bytes, as is typical of other I/O system calls, but a pointer to an array known as an I/O vector (not to be confused with an interrupt vector), and a count of the number of positions in the array. (The readv and writev system calls are for streams; there are similar system calls, recvmsg(2) and sendmsg(2), that you can use for datagrams.)
Every array position in the I/O vector is an iovec structure. Each iovec structure contains a pair of fields: a pointer to the data to be written or a buffer into which data will be read, and the length in bytes of the data to be read or written.

I take it from the comments in the header file that readv and writev were originally adapted from the Berkeley Software Distribution (BSD), a UNIX variant I cut my teeth on decades ago on a DEC VAX-11/750. But it was later, at the National Center for Atmospheric Research in Boulder Colorado, where I was introduced to vector I/O, which was used to read and write ginormous lists of floating point numbers used in the specialized vector supercomputers at that national lab. Those high performance machines could do many identical floating point operations in parallel on those data vectors, multiplying and dividing dozens of numbers together all at once. I'm told vector I/O also has its place in high performance graphics hardware.
But my interest in vector I/O comes from the many years I've spend working in protocol stacks for technologies, like Asynchronous Transfer Mode (ATM) and cellular base stations, in the telecommunications industry.
Vector I/O
Supposing you want to transmit a packet whose wire format - what it looks like as it is transmitted over the network, not necessarily what it looks like in memory - looks like this. (This is a pretty simple example compared to typical network protocols.)

The wire format has five fields: a four-byte IPv4 address, a two-byte port number, an eight-byte payload length (which would be overkill for sure), a variable length payload, and finally a two-byte (sixteen-bit) checksum.
These fields may not be in a contiguous location in memory in the protocol stack. In fact, because of memory alignment requirements for the different fields, it may be impossible for them to be contiguous without copying each field byte by byte into a buffer as character data. Furthermore, the way protocol stacks are designed, these fields are probably not managed by the same software layers. By way of a trivial example, when creating an outgoing packet: one layer dealing with the application and business logic generates the payload; another layer responsible for packaging the payload and insuring it arrives intact adds the length field to the beginning and the checksum to the end; and a third layer whose duty is to route the data to the recipient adds the address and port number to the beginning.
One way I've seen this handled in production software is to do a lot of data copying and recopying. That tends to be expensive in terms of time and memory usage. Another way (which I thought was pretty clever, I wish I'd thought of it) was to use double-ended buffers: a single buffer was passed through the layers, the application put its payload more or less in the middle of the buffer, and each successive layer prepended and appended fields to either end. This still involves a lot of data copying from application variables into a contiguous buffer. I wondered if I/O vectors could be yet another approach to solving this problem.
You may have read or heard about zero-copy I/O. This is not that. Vector I/O is a way to eliminate copying in the application from variables to a buffer. Zero-copy I/O is a way to eliminate copying between user space where the application runs and kernel space where the device driver runs. For example: the application makes a zero-copy system call to write a buffer out to a device, file, or network. Instead of making a copy of all the application data from user space to kernel space and then releasing the application buffer, the kernel instead takes ownership of the application buffer, and later asynchronously notifies the application that the I/O is complete. The application can't mess with its own buffer until this notification arrives. It's possible to use both vector I/O and zero-copy I/O to avoid both types of copying (although my test program doesn't do that).
The application using writev instead populates an iovec array with pointers to, and the lengths of, each data field. When the data is ready to be written onto the wire (file, device, or network), the writev system call steps through the array and writes each field one by one in order. (The Linux implementation makes sure this operation is atomic, so a writev running in one process or thread can't intermingle fields with another concurrent writev.)
For our example packet above, the iovec array would look like this.

Vector reads work similarly: the application using readv prepares an iovec array containing empty buffers and their lengths into which data will be read.
That's why this technique is sometimes referred to as scatter/gather: data read serially off the wire is scattered into separate memory locations instead of into a single contiguous buffer; data written to the wire is gathered from separate memory locations and serially written onto the wire.
I wanted to try out the various vector I/O system calls in Linux, so I wrote a little program to do just that. But I didn't want to do anything as prosaic just using iovec arrays. That would be too simple. I decided instead to try out an idea I've had for a long time: using a linked list to pass the data through the various software layers of a simulated protocol stack. And not any linked list, but the doubly-linked diminuto_list_t data structure I implemented in my Diminuto C systems programming library many years ago.
Lists
The Diminuto List implements a doubly-linked list - a linked list in which each node has a pointer to the next item on the list, as with a singly-linked list, and a pointer to the previous item on the list.
(You can find the source code for the Diminuto List implementation on GitHub at diminuto_list.h and diminuto_list.c.)

Singly- and doubly-linked lists are familiar to anyone who has taken Data Structures 101. Doubly-linked lists have an advantage over singly-linked lists in that a node can be removed or inserted anywhere on the list. Diminuto Lists (or just Lists, with a capital L, for brevity) have a few other features besides the next and previous links.

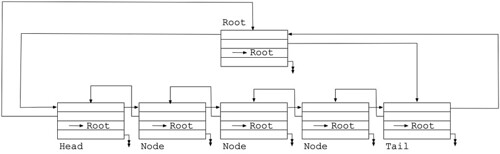
Each node on a List also has a link to the root of the list. This means that given any node on a List, you can find out what List it's on without traversing the List back to the root. So you can do things like trivially prepend or append a new node onto the same List as another node.
Diminuto Lists don't use null pointers, except for the data payload pointer, or as a returned value to indicate a specific condition. Lists are circular doubly-linked lists. The previous pointer on the node at the head of the List points back to the root note; the next pointer on the node at the tail of the List also points back to the root node. You know a node is at the head of the list because its previous pointer and its root pointer are the same. Similarly, a node is at the tail of the list because its next pointer and its root pointer are the same. When you insert a new node onto a List, that node inherits the root pointer from the node after which it was inserted.
Every Diminuto List node has a void * pointer that can point to a data payload. You can use this field by allocating nodes and payloads separately, and have each node point to its corresponding payload, whatever that is. Or you can embed an diminuto_list_t node structure as a field in the payload structure itself, and either ignore the data pointer, or use it to point to the beginning of the payload. You can have multiple node structures in a payload structure, so that the payload can exist on multiple Lists simultaneously; each node's payload pointer can point to the beginning of the containing structure; this eliminates the need to know which node structure you are using in a payload structure in order to compute the address of the beginning of the payload structure.
The root of a Diminuto List is just another node. You know it's the root node because its own root pointer is pointing to itself. Your application may choose to use the payload pointer in the root node for something, or just ignore it.
When a List node is newly initialized it looks like this.

The node's next pointer, its previous pointer, and its root pointer are all pointing to itself. It is in effect the root of an empty List. Whether it remains a root node depends on whether another node is inserted onto it (then it is), or it is inserted onto another List (then it isn't).
As you insert nodes, the next and previous pointers in the inserted node and the adjacent nodes, as well as the root pointer in the inserted node, are all adjusted appropriately. Similar when you remove a node. Because a List is circular, there are no special cases about inserting, removing, appending, or prepending, a node on a List. And you can splice an entire List into another List; the root pointers in the spliced List will all be rerooted to point to the root of the List onto which it is being spliced. You can cut out a sub-List from an existing List, and reroot that new List to a new root node.
If you have a Diminuto List with five nodes plus the sixth root node, it looks like this. (I abbreviated the root node pointers so as to not make the diagram too tangled.)
I don't use Diminuto Lists for everything: the overhead of the four pointers is overkill for applications where one suffices. But they have proven remarkable flexible. So it seemed like a good idea for this experiment.
Gather
The idea here is that different layers in the protocol stack incrementally build a packet by putting the value of each field to be transmitted into a payload buffer associated with a List node, then prepend or append (or even insert or replace) that node onto a List that will eventually represent the entire packet. When the packet is completely built, the application hands off the root node to a function which walks the entire List to build an I/O vector, and then passes the vector to a system call to put on the wire.
(You can find the source code for this test program on GitHub at unittest-ipc-scattergather.c.)
The highest layer of the stack puts a node whose data payload pointer points to a buffer containing the data to be transmitted. In my test program, these buffers are allocated from a pool (as are the List nodes, from a different pool), and each buffer has a length field at its beginning. The start of the data field of a buffer from the pool is eight-byte aligned, so that its address can be cast to be a pointer of an application variable or structure; that pointer can be used via indirect addressing without copying values. In my test program, the root node is referred to as a record, and the nodes with payload buffers are called segments.
The record is, of course, initially empty. Once the payload segment is put on the record, the record looks like this.

The next layer of the stack prepends a segment at the beginning of the record that contains the length of the data to be transmitted in an eight-byte field. (The length is just taken from the length field in the payload segment's data buffer). It appends a segment to the end of the record that contains a two-byte Fletcher-16 checksum field that it computed from the payload data. The record now looks like this.

The record gets passed to another layer that prepends two segments to the beginning of the record: one containing a four-byte IPv4 address, and another containing two-byte port number.

The record gets passed to a final layer that interrogates the address and port segments of the record to get the destination to which the record is to be sent. It then passes the record along with this information to a function which vectorizes the record: the function just walks the List from front to back, interrogating each segment for a pointer to the beginning of its data buffer and the value in that buffer's length field. It shoves each of these pairs of data into successive positions in the I/O vector. (This is the same figure as seen above.)
It then calls the appropriate system call, writev(2) for streams or sendmsg(2) for datagrams, which puts the resulting serialized packet on the wire. (This is also the same figure as above.)
This completes the gather portion of the I/O. (With the appropriate abstraction and packaging into supporting functions, this was all a lot easier to code than it sounds.)
Scatter
The scatter portion of the I/O is almost the same operation, but done in reverse. But there is a complication: the payload portion of the packet is variable length, so the application has no way of knowing ahead of time what how large a data buffer to assign to the segment the represents that payload field, or what length to put in the I/O vector for the system call.
For datagram sockets, I solved this problem by having four segments, for four fields - address, port, length, and payload - instead of five. The last segment has a data buffer that is large enough to contain the largest possible payload and the two-byte checksum. The datagram receiver in the test program has to extract the checksum from the end of the payload buffer once the length is known. Because, like all good software developers, I'm a little OCD, I added the checksum as another segment which I appended to the record, and adjusted the length field in the payload data buffer by two bytes.
This solution doesn't work for stream sockets, because if there is a second packet behind the one we are receiving, the beginning of that packet would be read into the larger payload buffer past the data of the prior packet. I solved this problem by doing two vector I/O operations: the first reads the address, port, and length; once the length is known, the second reads the payload and the checksum. This solution isn't possible for datagram sockets, since datagrams are transmitted and received as a single unit.
Or you can ditch the entire vector I/O scheme on the receiving end completely. As my test program illustrates, the sender can transmit the packet using vector I/O, but the receiver can receive the packet using any appropriate scheme it wants. My test program implements a variety of ways of doing this for both stream and datagram sockets.
Remarks
I wrote the unittest-ipc-scattergather.c test program as a sort of audition for adding this kind of capability to the mainstream Diminuto library. I'm not convinced that it has broad enough applicability to make that worthwhile. But I rest easier knowing that I have a usable List-vector I/O scheme with a working example in my hip pocket.
Update (2021-03-19)
Today I made the scatter/gather capability a mainstream Diminuto feature. The function and type names have been changed to reflect the canonical Diminuto style. The feature now supports both IPv4 and IPv6 sockets. Additional unit tests have been added. The unit tests are now part of the sanity test suite for Diminuto. All sanity tests pass.


No comments:
Post a Comment