You’ve heard the maxim that it’s far far more expensive to acquire a new customer than keep an existing one? Part of this is habit. Humans are for the most part creatures of habit. To keep an existing customer, you just need to keep feeding their habit (e.g. a latte every morning at the local Starbucks drive through), and not give them a reason to change it (e.g. keep botching their order). But to get a new customer, you have to get them to change their habits. You have to convince them to do your thing in place of whatever thing they've been doing. That’s a big deal.
I wonder how many of us are going to have our habits rewired due to all of this Coronavirus craziness. Sure, I used to go to Starbucks around 0600 every morning and read for an hour or two. Maybe when all this is over, I realize I can save a lot of calories and money by just making a cup of coffee at home - like I’ve been doing for the past several weeks... or months.
Yeah, I used to go to the gym six times a week. But maybe I can save a lot of time and effort by staying with doing those core floor exercises on my mat in the living room three times a week, and taking a long walk outside for cardio the other three times.
Maybe I learn an important lesson: I don’t really need Starbucks four dollar lattes, or an expensive gym membership.
Could be a lot of places are going to find out a lot of their regulars aren’t coming back.
Other ideas:
Businesses are slow to rehire, acting conservatively in the face of an uncertain future (H/T to Demian Neidetcher).
Businesses find their old employees have made other plans, so they are forced to hire new people who must be retrained, preventing them from achieving their prior level of service, at least anytime soon.
Businesses don't survive this, forcing us to make other accommodations anyway (H/T to Kelly Dixon).
I think it's going to be a substantially different world at the far end of all of this; not just politically and medically, but professionally and personally.
Tuesday, March 31, 2020
Saturday, March 21, 2020
Product Specifications
This is a photograph of a piece of paper going into the kind of paper shredder you would buy at your office supply store.

This model has two slots: the regular intake slot labelled "6 SHEET MAXIMUM" and the auto-feed slot labeled "75 SHEET MAXIMUM". I am in the process of destroying this shredder - which was brand new just a few days ago - or at least certainly violating its warranty, by exceeding its duty cycle: over the span of a couple of weeks, I'll be reducing several decades of financial paperwork to tiny bits of paper.
It occurred to me, as I spend hours feeding paper into this device, stopping occasionally to let it cool down, clearing jams, lubricating it, and cleaning some components using a procedure for sure not covered in the owner manual, that some folks might not know the real meaning of those "SHEET MAXIMUM" notations. As a professional product developer with more than four decades of experience, let me enlighten you.
Decades ago I worked at a national lab in Boulder Colorado. My boss, who had a Ph.D. in physics, used to say that any claims a supercomputer manufacturer made for the ginormous systems they sold were in effect guarantees that those systems could under no circumstances exceed those specifications. It didn't matter whether they were for instructions per second, floating point operations per second, disk I/Os per second, and so forth.
In the fullness of time, I, as a product developer, came to understand this was much more broadly applicable than just supercomputers. Applicable to both the devices I was trying to use in the products I was helping my clients develop and ship, and to those products themselves. In this latter capacity, I may have played a role in determining a product specification or two. It is even possible you have used some of those products.
Let's focus on the auto feed specification for my paper shredder: "75 SHEET MAXIMUM". What does this really mean?
In my basement, feeding ancient reports that had been folded, spindled, and mutilated, having sat all that time in a filing cabinet, with no climate control other than the nearby furnace which runs from time to time, reports from which I had just violently removed the staples I had inserted years ago, and having one of our beloved feline overlords supervising my efforts, I find that seven sheets sometimes works. And sometimes not.

That's what a product specification means.
This model has two slots: the regular intake slot labelled "6 SHEET MAXIMUM" and the auto-feed slot labeled "75 SHEET MAXIMUM". I am in the process of destroying this shredder - which was brand new just a few days ago - or at least certainly violating its warranty, by exceeding its duty cycle: over the span of a couple of weeks, I'll be reducing several decades of financial paperwork to tiny bits of paper.
It occurred to me, as I spend hours feeding paper into this device, stopping occasionally to let it cool down, clearing jams, lubricating it, and cleaning some components using a procedure for sure not covered in the owner manual, that some folks might not know the real meaning of those "SHEET MAXIMUM" notations. As a professional product developer with more than four decades of experience, let me enlighten you.
Decades ago I worked at a national lab in Boulder Colorado. My boss, who had a Ph.D. in physics, used to say that any claims a supercomputer manufacturer made for the ginormous systems they sold were in effect guarantees that those systems could under no circumstances exceed those specifications. It didn't matter whether they were for instructions per second, floating point operations per second, disk I/Os per second, and so forth.
In the fullness of time, I, as a product developer, came to understand this was much more broadly applicable than just supercomputers. Applicable to both the devices I was trying to use in the products I was helping my clients develop and ship, and to those products themselves. In this latter capacity, I may have played a role in determining a product specification or two. It is even possible you have used some of those products.
Let's focus on the auto feed specification for my paper shredder: "75 SHEET MAXIMUM". What does this really mean?
(Disclaimer: what follows is a completely fictional but probably highly accurate portrayal.)
At some point in time, an engineer, who probably had at least a master's degree in mechanical engineering, took one of these shredders and ran some tests on it. It was likely it was a laboratory mule used for prototyping and early firmware development, many months before the first production model came off the assembly line, since such a machine would have already had to have the manufacturing process established to print this label on the unit. This was done in a climate-controlled clean room environment, carefully cleaned and scrubbed, and devoid of any food or drink. The engineer - and indeed everyone in the lab - wore clean-room "bunny" suits, meticulously free of any foreign matter.
The engineer carefully installed brand new hand-sharpened blades; lovingly hand adjusted all the tolerances of all the moving parts, running bearings far more expensive than what would be used in the actual production unit, and carefully lubricated all the parts using the most expensive lubricant from his lab supplies.
The engineer used brand new paper, right out of the box, devoid of any toner, perfectly flat, and as thin as was available commercially, but not too thin. The engineer cleaned the paper with aerosol canned air, fanned the stack of paper out to make sure none of the pages stuck together, and checked that each page was momentarily grounded to eliminate any static electricity.
The engineer carefully started testing the printer, using a pair of calibers and a stainless steel ruler to make sure the stack of paper in the input bin of the shredder was precisely aligned. The engineer tested stack after stack, adding one single page to each test. For each test, the engineer took the temperature of the electric motors in the shredder, making sure they were not overtaxed, allowing the shredder to cool down completely, probably overnight, in between each test. Each morning, the engineer relubricated and realigned all the mechanical bits in the prototype, possibly replacing any parts that showed the most minuscule amounts of wear when viewed under a laboratory microscope costing tens of thousands of dollars.
When the engineer reached seventy-six pages, the shredder exploded. The shrapnel killed everyone in the room. The shredding blades were especially lethal.
The engineer's supervisor, who had an MBA, came into the room, read the final number off the engineer's laboratory notebook, and notified manufacturing what the limit was: seventy-five sheets."75 SHEET MAXIMUM" means seventy-five is the limit under the most optimal, controlled conditions that are humanly possible in the most optimistic of all conceivable circumstances.
In my basement, feeding ancient reports that had been folded, spindled, and mutilated, having sat all that time in a filing cabinet, with no climate control other than the nearby furnace which runs from time to time, reports from which I had just violently removed the staples I had inserted years ago, and having one of our beloved feline overlords supervising my efforts, I find that seven sheets sometimes works. And sometimes not.
That's what a product specification means.
Monday, March 16, 2020
Placer: X Macros, SQLite, and Schema
In every learning project, I try to have at least two goals. In Placer, I wanted to re-learn how to use SQLite, and to remember how to make use of X macros.
SQLite - pronounced S Q L -ite, like a mineral - is the server-less library-based embeddable relational database system that supports the Structured Query Language or SQL. It is likely running inside a mobile device near you. It ships inside every iOS device, every Android device, most web browsers, and (rumor has it) Windows 10. It has been said that SQLite is the most widely deployed database system in the world, a claim I find plausible.
X macros are perhaps the most egregious use of the C preprocessor outside of the International Obfuscated C Code Contest. This isn't my first rodeo with SQLite, nor with X macros, nor with the application of X macros to using SQLite, having seen other developers who were a lot smarter than me do this kind of thing in a large embedded telecommunications project about thirteen years ago.
In the Placer repo, the C header file SchemaPath.h contains the following. (You can click on any of these images to see a larger version.)
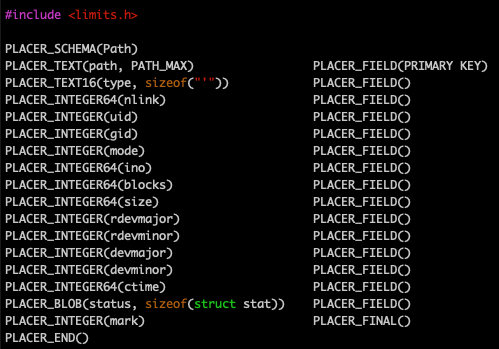
As you might guess, this code - somehow - describes the schema of a database table called Path. Every row in Path contains sixteen fields, named path, type, nlink, and so forth. The terms TEXT, TEXT16, INTEGER64, INTEGER, and BLOB, determine the type of the data that will be contained in the field. It seems likely that the field path is the primary key for the table. Some of the fields seem to be arrays, since they have an additional parameter that indicates a size.
So what are these operators, PLACER_SCHEMA, PLACER_INTEGER, and so forth? They look like invocations of C preprocessor macros. Except the macros aren't defined here. Which is a good thing, because this header file doesn't have any #if #endif guards to keep the contents of this header file from being seen more than once. Because we are going to include it more than once. We're going to include it a lot.
In the functional test program survey.c, the following snippet of code can be found.

Now you're guessing that com/diag/placer/placer_structure_definition.h defines these macros. I'll cut to the chase and tell you that com/diag/placer/placer_end.h undefines them just to keep the prior definitions from bleeding into later code.
When the C preprocessor includes these files and processes them, the following code is generated.
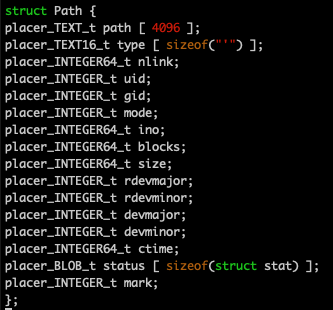
That's because the file com/diag/placer/placer_structure_definition.h contains the following preprocessor code.
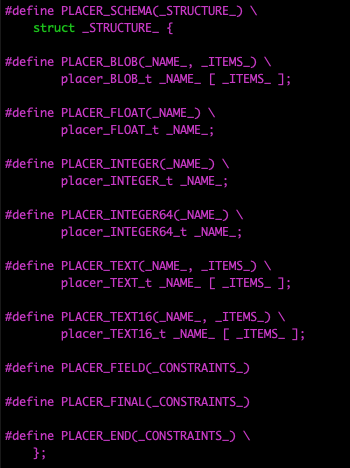
That seems pretty straightforward. The macros create a C structure definition that can be used to create an object that can store the data found in a single row in the Path table.
In a function in survey.c that adds a new row to the Path table, the following code snippet can be found.

When these header files are read and processed, the following C code is generated.
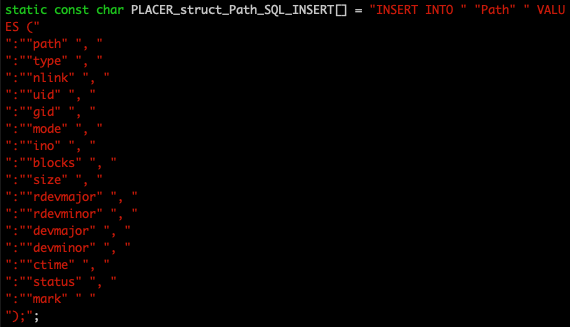
That's because the header file com/diag/placer/placer_sql_insert.h contains a different set of definitions for the same schema macros.
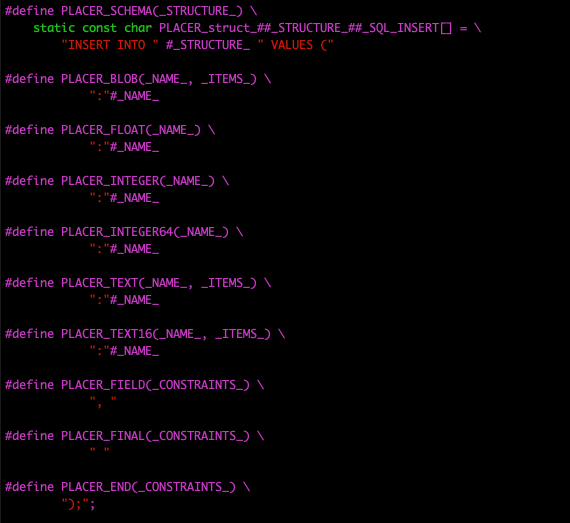
This generates an SQL INSERT command will direct SQLite to insert a new row of data into the table Path. But where's the actual data? SQLite allows the application to bind the actual data to this command by identifying each field not by its field name, but by a one-based index number. But we need a set of calls to the type-appropriate SQLite bind functions to do this.
By now, it will come as no surprise that

generates the following code (keeping in mind that code generated by the C preprocessor is not meant for humans to grok, but is easily understood by the C compiler)
because the header file com/diag/placer/placer_stmt_bind.h once again redefines the schema macros
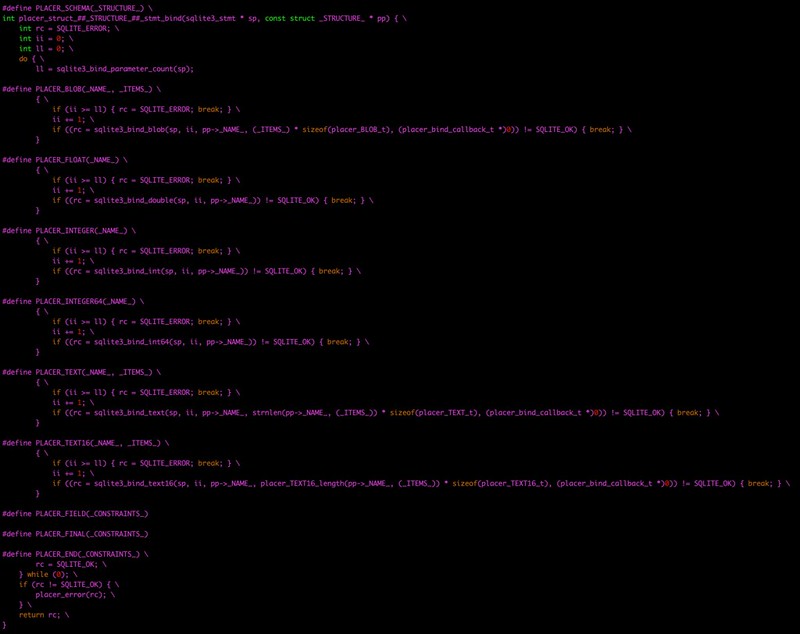
doing the exact right thing for each individual field according to both its position in the INSERT statement and its data type.
All of this code is generated automatically by the preprocessor. All survey.c has to do is define the schema in one header file, which it calls SchemaPath.h, and then include it along with the appropriate header files containing C macro definitions.
In the end, given an automatically generated C structure, an automatically generated SQL command, and an automatically generated bind function, survey.c just does this to add a new row into the Path table. (In the snippet below, schema is the name of an object of type struct Path.)
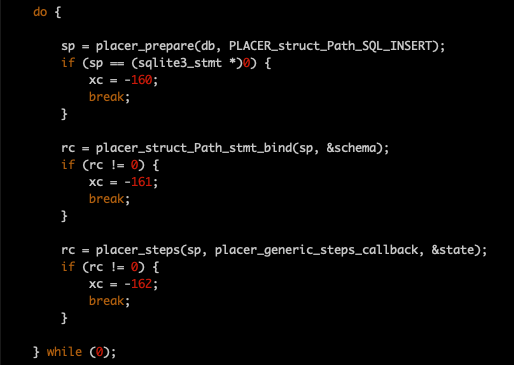
The symbol placer_generic_steps_callback above is the name of a callback function that handles the normal housekeeping of inserting a new row into any table of any database. But suppose you need to do something more complicated, like read a row, or a collection of rows from table Path?
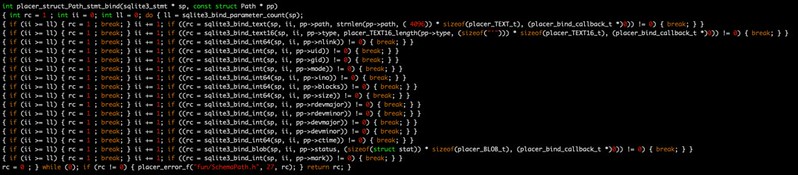
In the snippet below, the code is doing an SQL SELECT from Path for zero to no more than eight rows whose value of ino (a field that turns out to be the unique inode number for a particular file in the file system whose metadata is held in the database) matches that of the variable ino that was read from the command line. We just use SQLite's bind function for integers to bind the value of the variable ino to the parameterized SELECT statement.

SQLite will read rows from the Path table in the database and provide them one at a time to the callback function placer_struct_Path_steps_callback, and then the function placer_struct_Path_display is used to display them on a FILE stream.
You know where this is going.

generates

using the macros defined in com/diag/placer/placer_steps_callback.h (not all macro definitions shown)

to load successive rows from the table into successive instances of the Path structure.
Similarly

generates

using the macros defined in com/diag/placer/placer_structure_display.h (ditto)
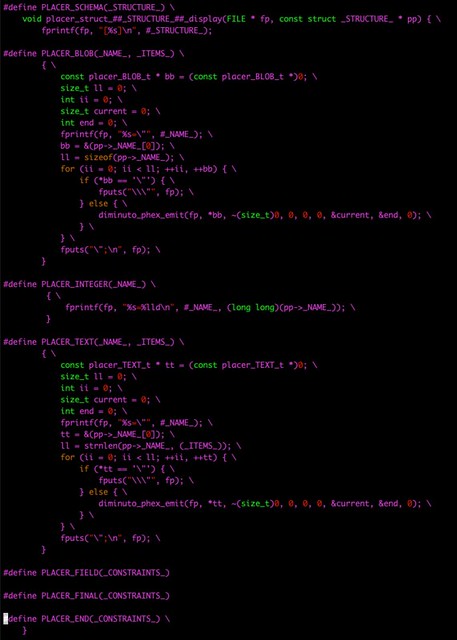
to display each field in a selected row appropriately.
It's just that simple.
No, really. All the heavy lifting is done by the header files that are all predefined (and tested). The x macros in Placer make the transition between the C structure and the table row as delivered to and from SQLite pretty straightforward.
As I said before, I didn't come up with this technique originally. The folks I learned it from long ago may have been the first to apply it to SQLite, I don't know. But this application of C preprocessor macros - in a manner that is just the opposite of how most developers think of using them - had already been around for many years.
The com-diag-placer repository of implementation, unit tests, and functional tests, with documentation generated using Doxygen, is available on GitHub. It is licensed under the GNU LGPL 2.1.
SQLite - pronounced S Q L -ite, like a mineral - is the server-less library-based embeddable relational database system that supports the Structured Query Language or SQL. It is likely running inside a mobile device near you. It ships inside every iOS device, every Android device, most web browsers, and (rumor has it) Windows 10. It has been said that SQLite is the most widely deployed database system in the world, a claim I find plausible.
X macros are perhaps the most egregious use of the C preprocessor outside of the International Obfuscated C Code Contest. This isn't my first rodeo with SQLite, nor with X macros, nor with the application of X macros to using SQLite, having seen other developers who were a lot smarter than me do this kind of thing in a large embedded telecommunications project about thirteen years ago.
Disclaimer: I'm not a database person, even though I took a database class that covered (even then) relational databases, more than forty years ago. It doesn't seem to have changed that much.SQLite is a relational database. So, conceptually anyway, a relational database organizes data in one or more tables. Each table contains rows. Each row contains different instances of the same collection of fields. One of the fields is identified as a primary key, a field that contains a unique value identifying a specific row in the table. The database system can optimize its indexing such that retrievals by the primary key can access a specific row very quickly, without scanning every row in the table. In this context, the term schema is used to describe the design and format of a relational database table.
In the Placer repo, the C header file SchemaPath.h contains the following. (You can click on any of these images to see a larger version.)
As you might guess, this code - somehow - describes the schema of a database table called Path. Every row in Path contains sixteen fields, named path, type, nlink, and so forth. The terms TEXT, TEXT16, INTEGER64, INTEGER, and BLOB, determine the type of the data that will be contained in the field. It seems likely that the field path is the primary key for the table. Some of the fields seem to be arrays, since they have an additional parameter that indicates a size.
So what are these operators, PLACER_SCHEMA, PLACER_INTEGER, and so forth? They look like invocations of C preprocessor macros. Except the macros aren't defined here. Which is a good thing, because this header file doesn't have any #if #endif guards to keep the contents of this header file from being seen more than once. Because we are going to include it more than once. We're going to include it a lot.
In the functional test program survey.c, the following snippet of code can be found.
Now you're guessing that com/diag/placer/placer_structure_definition.h defines these macros. I'll cut to the chase and tell you that com/diag/placer/placer_end.h undefines them just to keep the prior definitions from bleeding into later code.
When the C preprocessor includes these files and processes them, the following code is generated.
That's because the file com/diag/placer/placer_structure_definition.h contains the following preprocessor code.
That seems pretty straightforward. The macros create a C structure definition that can be used to create an object that can store the data found in a single row in the Path table.
In a function in survey.c that adds a new row to the Path table, the following code snippet can be found.
When these header files are read and processed, the following C code is generated.
That's because the header file com/diag/placer/placer_sql_insert.h contains a different set of definitions for the same schema macros.
This generates an SQL INSERT command will direct SQLite to insert a new row of data into the table Path. But where's the actual data? SQLite allows the application to bind the actual data to this command by identifying each field not by its field name, but by a one-based index number. But we need a set of calls to the type-appropriate SQLite bind functions to do this.
By now, it will come as no surprise that
generates the following code (keeping in mind that code generated by the C preprocessor is not meant for humans to grok, but is easily understood by the C compiler)
because the header file com/diag/placer/placer_stmt_bind.h once again redefines the schema macros
doing the exact right thing for each individual field according to both its position in the INSERT statement and its data type.
All of this code is generated automatically by the preprocessor. All survey.c has to do is define the schema in one header file, which it calls SchemaPath.h, and then include it along with the appropriate header files containing C macro definitions.
In the end, given an automatically generated C structure, an automatically generated SQL command, and an automatically generated bind function, survey.c just does this to add a new row into the Path table. (In the snippet below, schema is the name of an object of type struct Path.)
The symbol placer_generic_steps_callback above is the name of a callback function that handles the normal housekeeping of inserting a new row into any table of any database. But suppose you need to do something more complicated, like read a row, or a collection of rows from table Path?
In the snippet below, the code is doing an SQL SELECT from Path for zero to no more than eight rows whose value of ino (a field that turns out to be the unique inode number for a particular file in the file system whose metadata is held in the database) matches that of the variable ino that was read from the command line. We just use SQLite's bind function for integers to bind the value of the variable ino to the parameterized SELECT statement.
SQLite will read rows from the Path table in the database and provide them one at a time to the callback function placer_struct_Path_steps_callback, and then the function placer_struct_Path_display is used to display them on a FILE stream.
You know where this is going.
generates
using the macros defined in com/diag/placer/placer_steps_callback.h (not all macro definitions shown)
to load successive rows from the table into successive instances of the Path structure.
Similarly
generates
using the macros defined in com/diag/placer/placer_structure_display.h (ditto)
to display each field in a selected row appropriately.
It's just that simple.
No, really. All the heavy lifting is done by the header files that are all predefined (and tested). The x macros in Placer make the transition between the C structure and the table row as delivered to and from SQLite pretty straightforward.
As I said before, I didn't come up with this technique originally. The folks I learned it from long ago may have been the first to apply it to SQLite, I don't know. But this application of C preprocessor macros - in a manner that is just the opposite of how most developers think of using them - had already been around for many years.
The com-diag-placer repository of implementation, unit tests, and functional tests, with documentation generated using Doxygen, is available on GitHub. It is licensed under the GNU LGPL 2.1.
Monday, March 09, 2020
When Learning By Doing Goes To Eleven
There are different modes of learning, and each modality works best for different people. I am always envious of my friends and colleagues who can learn by reading a book. That never worked for me. I can only learn by doing, albeit sometimes with a book or web page propped up in front of me. This explains why I have over thirty repositories on GitHub. And why I have a GPS-disclipined stratum-0 NTP server with a cesium chip-scale atomic clock in my living room.

Some of my repos on GitHub are standalone projects, like the stratum-0 server or my learning experiences with Go and Rust. But some of them follow a pattern: my project implements a Linux/GNU-based framework implemented in C as a library and a set of header files, then some unit tests, then some functional tests, then maybe some tools I found useful. Why C? Because for the past few decades, most of my income has come from working on embedded and real-time systems, close to bare metal, in C and sometimes C++. C and C++ have been very very good to me. Although I do admit to some hacking now and then in Java, Python, and occasionally even in JavaScript (although I couldn't write a line of JavaScript from scratch even if my life depended on it).
While more or less wrapping up my most recent C-based learning project, it occurred to me that maybe there was an overall pattern to these C frameworks. I had incorporated decades of experience working in ginormous C and C++ code bases into their architecture and the design of their APIs, being careful to make sure they could be used together. I started to wonder if I was subconsciously working towards some greater goal. So I decided to list these frameworks here, all in one place, for the first time, mostly for my own benefit, in the hope the bigger picture would reveal itself.
So here they are, in no particular order. Some of these projects have been around long enough that I have ported them through four different source code control systems. All of them have been cloned, built, tested, and used on
Hazer
Description: Parse NMEA and other typical output from GNSS devices.
Inception: 2017
Repository: https://github.com/coverclock/com-diag-hazer
Playlist: https://www.youtube.com/playlist?list=PLd7Yo1333iA9FMHIG_VmuBCVTQUzB-BZF
Hazer started out as a way for me to learn the National Marine Equipment Association (NMEA) standard used to describe the output of virtually all GPS, and later GNSS, devices. I had encountered NMEA with GPS in many embedded projects over the years, but had never dealt with it from scratch. Hazer was so useful, it evolved into a tool to test GPS/GNSS devices, then to implement other more specific projects like a moving map display and vehicle tracker when integrated with Google Earth, GPS-disciplined NTP servers, and most recently a differential GNSS system with a fixed base station and a mobile rover.
Articles:
Having written parsers and lexical scanners when I was in graduate school (one in Prolog, if you can believe it), long before I ever had access to a UNIX system, I was naturally interested in learning how to use yacc and lex. In some of my commercial work I routinely encountered INI-format configuration files. Those seemed to be generally useful things, with a format that was easier for humans to grok than the XML or JSON files I routinely dealt with too. So I implemented an INI file parser using the GNU counterparts bison and flex, using a syntax that was more or less based on the countless INI implementation I found in the field. The parser includes the ability to run a process and collect its output as the value of the property, which makes for some entertaining capabilities.
Articles:
All of the other projects in this list rely on Diminuto to provide common underlying facilities. Diminuto started out as a project to build a minimal Linux 2.4 system on top of an ARMv4 processor. Over time, the framework and library became far more important than the original goal. Portions of Diminuto are now shipping in at least four different products manufactured by various clients (whether they realize it or not).
When I implement a feature in any C-based project, I pause and consider whether it might be more generally useful. If I decide that it is, I implement it in Diminuto instead of the root project. Diminuto has thus grown organically to include a bunch of useful stuff, only a small portion of which is listed here.
Some of my repos on GitHub are standalone projects, like the stratum-0 server or my learning experiences with Go and Rust. But some of them follow a pattern: my project implements a Linux/GNU-based framework implemented in C as a library and a set of header files, then some unit tests, then some functional tests, then maybe some tools I found useful. Why C? Because for the past few decades, most of my income has come from working on embedded and real-time systems, close to bare metal, in C and sometimes C++. C and C++ have been very very good to me. Although I do admit to some hacking now and then in Java, Python, and occasionally even in JavaScript (although I couldn't write a line of JavaScript from scratch even if my life depended on it).
While more or less wrapping up my most recent C-based learning project, it occurred to me that maybe there was an overall pattern to these C frameworks. I had incorporated decades of experience working in ginormous C and C++ code bases into their architecture and the design of their APIs, being careful to make sure they could be used together. I started to wonder if I was subconsciously working towards some greater goal. So I decided to list these frameworks here, all in one place, for the first time, mostly for my own benefit, in the hope the bigger picture would reveal itself.
So here they are, in no particular order. Some of these projects have been around long enough that I have ported them through four different source code control systems. All of them have been cloned, built, tested, and used on
- x86_64 i7-7567U,
- x86_64 i7-5557U, and
- ARMv7 BCM2835
- Ubuntu 18.04 "bionic",
- Ubuntu 19.04 "disco", and
- Raspbian 10 "buster"
Hazer
Description: Parse NMEA and other typical output from GNSS devices.
Inception: 2017
Repository: https://github.com/coverclock/com-diag-hazer
Playlist: https://www.youtube.com/playlist?list=PLd7Yo1333iA9FMHIG_VmuBCVTQUzB-BZF
Hazer started out as a way for me to learn the National Marine Equipment Association (NMEA) standard used to describe the output of virtually all GPS, and later GNSS, devices. I had encountered NMEA with GPS in many embedded projects over the years, but had never dealt with it from scratch. Hazer was so useful, it evolved into a tool to test GPS/GNSS devices, then to implement other more specific projects like a moving map display and vehicle tracker when integrated with Google Earth, GPS-disciplined NTP servers, and most recently a differential GNSS system with a fixed base station and a mobile rover.
Articles:
- Better Never Than Late, https://coverclock.blogspot.com/2017/02/better-never-than-late.html
- My WWVB Radio Clock, https://coverclock.blogspot.com/2017/10/my-wwvb-radio-clock.html
- A Menagerie of GPS Devices, https://coverclock.blogspot.com/2018/04/a-menagerie-of-gps-devices-with-usb.html
- Practical Geolocation, https://coverclock.blogspot.com/2018/08/practical-geolocation.html
- Practical Geolocation II, https://coverclock.blogspot.com/2018/08/practical-geolocation-ii.html
- GPS Satellite PRN 4, https://coverclock.blogspot.com/2018/11/gps-satellite-prn-4.html
- Monitoring GPS and NTP, https://coverclock.blogspot.com/2018/12/monitoring-gps-and-ntp-yet-another.html
Assay
Description: Parse INI-format configuration files using bison and flex.
Inception: 2015
Repository: https://github.com/coverclock/com-diag-assay
Playlist: https://www.youtube.com/playlist?list=PLd7Yo1333iA-YIyldvOB56QS-HZed_4g1Having written parsers and lexical scanners when I was in graduate school (one in Prolog, if you can believe it), long before I ever had access to a UNIX system, I was naturally interested in learning how to use yacc and lex. In some of my commercial work I routinely encountered INI-format configuration files. Those seemed to be generally useful things, with a format that was easier for humans to grok than the XML or JSON files I routinely dealt with too. So I implemented an INI file parser using the GNU counterparts bison and flex, using a syntax that was more or less based on the countless INI implementation I found in the field. The parser includes the ability to run a process and collect its output as the value of the property, which makes for some entertaining capabilities.
Articles:
- Configuration Files Are Just Another Form Of Message Passing, https://coverclock.blogspot.com/2015/03/configuration-files-are-just-another.html
Codex
Description: Provide a slightly simpler C API to OpenSSL and BoringSSL.
Inception: 2018
Repository: https://github.com/coverclock/com-diag-codex
I had never written C code to directly use the various libraries that each implement the Secure Socket Layer (SSL). And I knew I was in for a lengthy learning experience, as I learned about all the stuff that came along with it: keys and their generation, certificate verification and revocation, encryption algorithms and methods, and so forth. I was fortunate to have a native guide: my old office mate from my Bell Labs days was deeply into all of this, and was generous to a fault with his time and expertise. In the end I not only learned the basics of effectively using OpenSSL and its variants, but also came up with a slightly simplified API that I was confident that I could use in other applications.
Articles:
- Using The Open Secure Socket Layer In C, https://coverclock.blogspot.com/2018/04/using-open-secure-socket-layer-in-c.html
Placer
Description: Automate C-based schema generation for the SQLite 3 RDBMS.
Inception: 2020
Repository: https://github.com/coverclock/com-diag-placer
My most recent project entailed my getting back into SQLite, the embeddable server-less SQL relational database management system. SQLite is used in every iOS device, every Android device, and (rumor has it) Windows 10. It is said to be the most widely deployed DBMS in the world, and it seems likely that this is true. Many Linux-based embedded products I've worked on in the past used SQLite to manage persistent data. But I'd never coded up an SQLite application myself from scratch. So: yet another learning experience. I always try to accomplish more than one goal with every project; in this one, it was to leverage x-macros - perhaps the most twisted use of the C preprocessor outside of the International Obfuscated C Code Contest - to automate the generation of C structures, functions, and variables to implement user-defined schemas for database tables. I still have a lot to learn about SQLite, but there is a lot of useful knowledge encapsulated in the library, unit tests, and functional tests for this project.
Articles: (none yet)
Diminuto
Description: Implement commonly useful C systems programming capabilities.
Inception: 2008
Repository: https://github.com/coverclock/com-diag-diminuto
- a simple mechanism to debounce digital I/O pins;
- a demonization function;
- an API to handle time and data stamps, time and duration measurement, and time delays;
- functions to expand and collapse C-style escape sequences in strings;
- a socket API that supports outgoing and incoming IPv4 and IPv6 connections;
- a logging API that writes to the system log if the caller is a daemon, or to standard error if not;
- a simplified API for socket and file descriptor multiplexing;
- an API to configure serial ports;
- a traffic shaping API based on the virtual scheduling algorithm;
- a red-black tree implementation;
- a simple unit test framework;
- a file system walker.
Articles:
- Some Stuff That Has Worked For Me In C, https://coverclock.blogspot.com/2017/04/some-stuff-that-has-worked-for-me-in-c.html
- When The Silicon Meets The Road, https://coverclock.blogspot.com/2018/07/when-silicon-meets-road.html
Update (2020-03-11)
If you install the doxygen, TeX, and LaTeX packages documented in the Makefile comments for the documentation make target for each of these projects, you can generate HTML and PDF documentation for each library via make documentation readme manuals. The build artifacts will be in subdirectories under out/host/doc in each build directory (with host being replaced with whatever you used for TARGET if you changed it).
If you install the doxygen, TeX, and LaTeX packages documented in the Makefile comments for the documentation make target for each of these projects, you can generate HTML and PDF documentation for each library via make documentation readme manuals. The build artifacts will be in subdirectories under out/host/doc in each build directory (with host being replaced with whatever you used for TARGET if you changed it).
Saturday, March 07, 2020
Considerations for Ethical Decision Making
JJ Snow, U. S. Air Force CTO, passed this along: considerations for ethical decision making for the U.S. Special Operations Forces from the Joint Special Operations University. I think it is a lot more broadly applicable than just to the SOF community: business, politics, governance, academia, science, etc. I'd argue that these are important guidelines for anyone who manages people in today's organizational environments. Substitute manager for SOF operator and management for SOF and see what you think. I found it made for thought provoking reading. (Cut and pasted from LinkedIn.)
She writes:
She writes:
What should guide us in tough times? Critical thinking, ethics, compassion and morality.
Joint Special Operations University proposed six SOF ethical decision-making truths:
1. Individual moral character is neither inherent nor fixed. Ethical decision-making requires continuing education for even the most experienced SOF operators.
2. SOF operators will be morally challenged when they are least prepared to deal with it. Ethical problem-solving skills must be developed and strengthened.
3. SOF ethical decision-making must be developed with honest and frank consideration for the harsh realities of SOF environments and operational requirements. SOF units must see the world for the way it is, not for how they might want it to be.
4. Binary ethical codes do not provide sufficient guidance in SOF environments. In fact, strict adherence to binary ethical codes can be harmful in some SOF environments.
5. SOF leaders should not be naïve or insensitive to human behavior and must recognize that people are not as ethical as they think they are. SOF operators need training to close the gap between the expectation and reality of what they must do.
6. SOF culture must become an environment where conversations about ethical decisions, good and bad, are a natural occurrence.
Subscribe to:
Posts (Atom)

