SQLite - pronounced S Q L -ite, like a mineral - is the server-less library-based embeddable relational database system that supports the Structured Query Language or SQL. It is likely running inside a mobile device near you. It ships inside every iOS device, every Android device, most web browsers, and (rumor has it) Windows 10. It has been said that SQLite is the most widely deployed database system in the world, a claim I find plausible.
X macros are perhaps the most egregious use of the C preprocessor outside of the International Obfuscated C Code Contest. This isn't my first rodeo with SQLite, nor with X macros, nor with the application of X macros to using SQLite, having seen other developers who were a lot smarter than me do this kind of thing in a large embedded telecommunications project about thirteen years ago.
Disclaimer: I'm not a database person, even though I took a database class that covered (even then) relational databases, more than forty years ago. It doesn't seem to have changed that much.SQLite is a relational database. So, conceptually anyway, a relational database organizes data in one or more tables. Each table contains rows. Each row contains different instances of the same collection of fields. One of the fields is identified as a primary key, a field that contains a unique value identifying a specific row in the table. The database system can optimize its indexing such that retrievals by the primary key can access a specific row very quickly, without scanning every row in the table. In this context, the term schema is used to describe the design and format of a relational database table.
In the Placer repo, the C header file SchemaPath.h contains the following. (You can click on any of these images to see a larger version.)
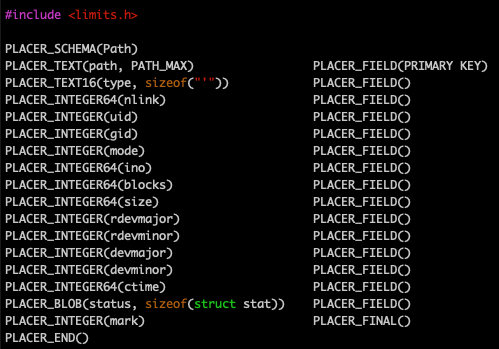
As you might guess, this code - somehow - describes the schema of a database table called Path. Every row in Path contains sixteen fields, named path, type, nlink, and so forth. The terms TEXT, TEXT16, INTEGER64, INTEGER, and BLOB, determine the type of the data that will be contained in the field. It seems likely that the field path is the primary key for the table. Some of the fields seem to be arrays, since they have an additional parameter that indicates a size.
So what are these operators, PLACER_SCHEMA, PLACER_INTEGER, and so forth? They look like invocations of C preprocessor macros. Except the macros aren't defined here. Which is a good thing, because this header file doesn't have any #if #endif guards to keep the contents of this header file from being seen more than once. Because we are going to include it more than once. We're going to include it a lot.
In the functional test program survey.c, the following snippet of code can be found.

Now you're guessing that com/diag/placer/placer_structure_definition.h defines these macros. I'll cut to the chase and tell you that com/diag/placer/placer_end.h undefines them just to keep the prior definitions from bleeding into later code.
When the C preprocessor includes these files and processes them, the following code is generated.
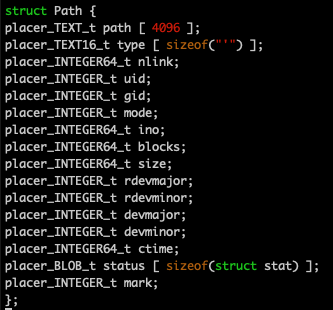
That's because the file com/diag/placer/placer_structure_definition.h contains the following preprocessor code.
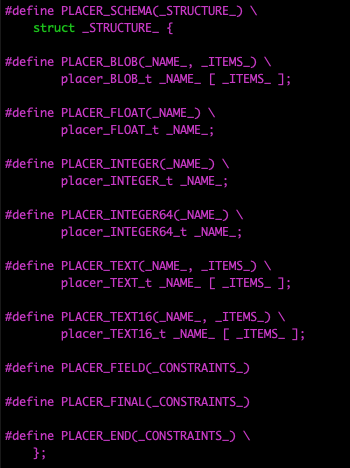
That seems pretty straightforward. The macros create a C structure definition that can be used to create an object that can store the data found in a single row in the Path table.
In a function in survey.c that adds a new row to the Path table, the following code snippet can be found.

When these header files are read and processed, the following C code is generated.
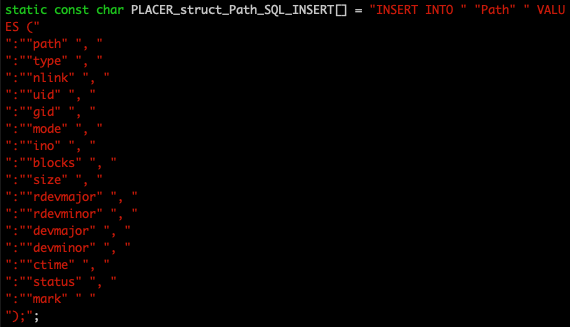
That's because the header file com/diag/placer/placer_sql_insert.h contains a different set of definitions for the same schema macros.
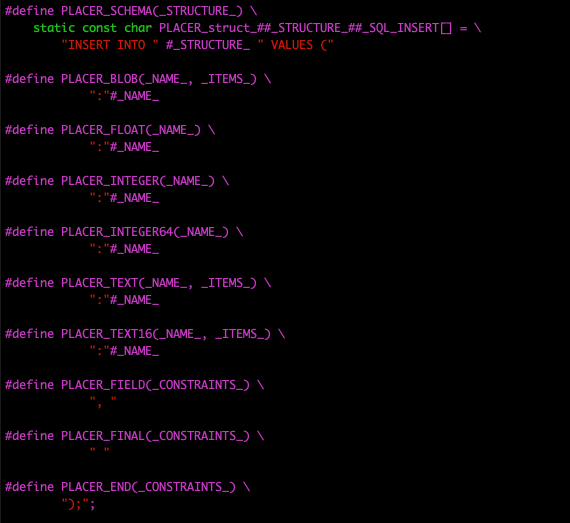
This generates an SQL INSERT command will direct SQLite to insert a new row of data into the table Path. But where's the actual data? SQLite allows the application to bind the actual data to this command by identifying each field not by its field name, but by a one-based index number. But we need a set of calls to the type-appropriate SQLite bind functions to do this.
By now, it will come as no surprise that

generates the following code (keeping in mind that code generated by the C preprocessor is not meant for humans to grok, but is easily understood by the C compiler)
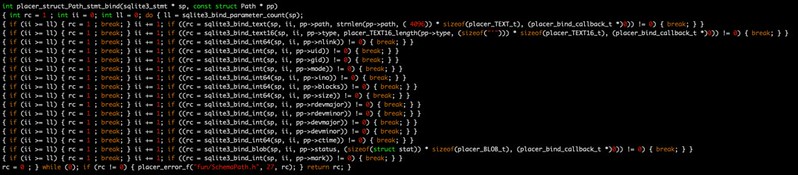
because the header file com/diag/placer/placer_stmt_bind.h once again redefines the schema macros
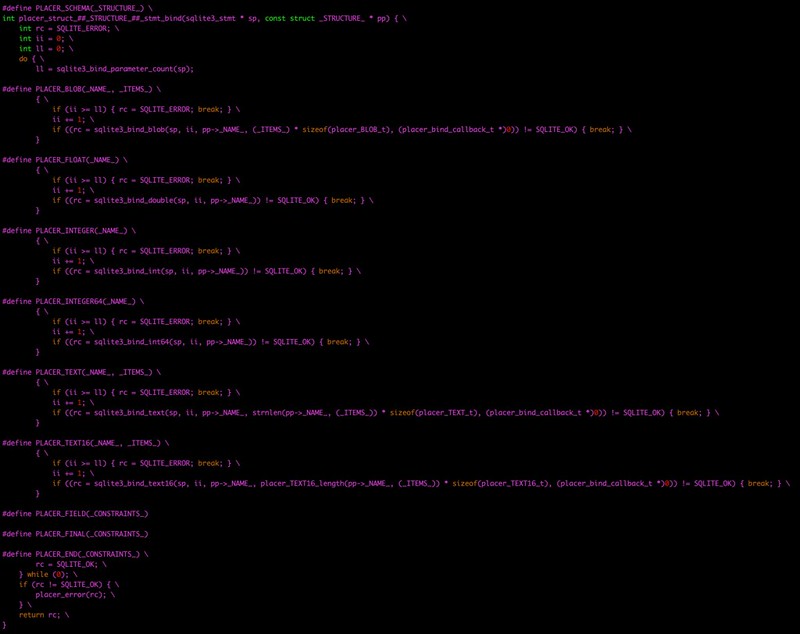
doing the exact right thing for each individual field according to both its position in the INSERT statement and its data type.
All of this code is generated automatically by the preprocessor. All survey.c has to do is define the schema in one header file, which it calls SchemaPath.h, and then include it along with the appropriate header files containing C macro definitions.
In the end, given an automatically generated C structure, an automatically generated SQL command, and an automatically generated bind function, survey.c just does this to add a new row into the Path table. (In the snippet below, schema is the name of an object of type struct Path.)
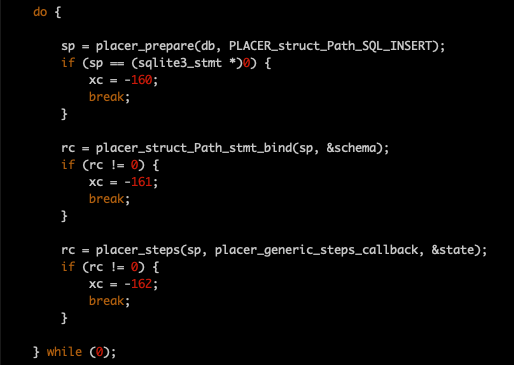
The symbol placer_generic_steps_callback above is the name of a callback function that handles the normal housekeeping of inserting a new row into any table of any database. But suppose you need to do something more complicated, like read a row, or a collection of rows from table Path?
In the snippet below, the code is doing an SQL SELECT from Path for zero to no more than eight rows whose value of ino (a field that turns out to be the unique inode number for a particular file in the file system whose metadata is held in the database) matches that of the variable ino that was read from the command line. We just use SQLite's bind function for integers to bind the value of the variable ino to the parameterized SELECT statement.

SQLite will read rows from the Path table in the database and provide them one at a time to the callback function placer_struct_Path_steps_callback, and then the function placer_struct_Path_display is used to display them on a FILE stream.
You know where this is going.

generates

using the macros defined in com/diag/placer/placer_steps_callback.h (not all macro definitions shown)

to load successive rows from the table into successive instances of the Path structure.
Similarly

generates

using the macros defined in com/diag/placer/placer_structure_display.h (ditto)
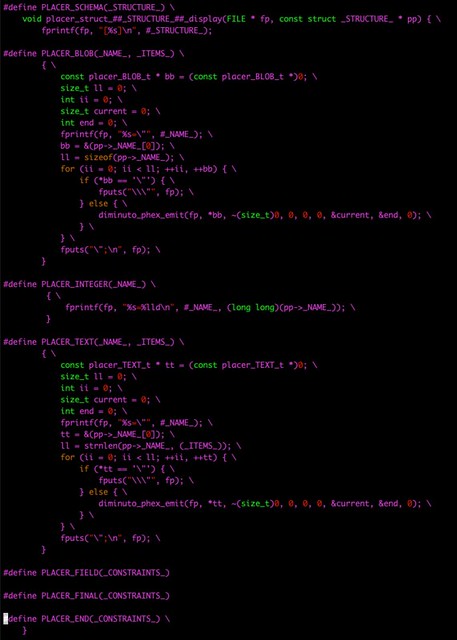
to display each field in a selected row appropriately.
It's just that simple.
No, really. All the heavy lifting is done by the header files that are all predefined (and tested). The x macros in Placer make the transition between the C structure and the table row as delivered to and from SQLite pretty straightforward.
As I said before, I didn't come up with this technique originally. The folks I learned it from long ago may have been the first to apply it to SQLite, I don't know. But this application of C preprocessor macros - in a manner that is just the opposite of how most developers think of using them - had already been around for many years.
The com-diag-placer repository of implementation, unit tests, and functional tests, with documentation generated using Doxygen, is available on GitHub. It is licensed under the GNU LGPL 2.1.


No comments:
Post a Comment