In "Unintended Consequences of the Information Economy II" (2021), I mentioned an Executive Order issued in May of this year (2021) by the Biden White House: "Executive Order on Improving the Nation's Cybersecurity". This morning over a leisurely Christmas Eve breakfast I read the fifty-four page EO from start to finish. (It's not that onerous; the way it is formatted on the White House web site, with very short lines, it was expeditious to print it two web pages per physical page.)
I'm tempted to say that I've never read an EO before, so I didn't know what to expect. I've read so much stuff over the past decades, I can't say for certain. (I once found myself having to read U.S Department of State International Traffic in Arms Regulations in regards to a commercial product I was helping develop for the business aviation space.) But for sure, I didn't expect the EO to be as interesting (or as readable) as it was. Here are some of the things I consider highlights:
There was a a lot of verbiage about the need for federal agencies to share information with one another on malicious cyber campaigns. This may seem obvious, but in many organizations - government and commercial - this might be a hard sell. There is little incentive for organizations to admit they've been hacked, for lots of reasons. So an EO which requires federal agencies to do so is probably a good thing.
There was also a lot of talk about the need for vendors who sell into the federal government space, especially cloud service providers (CSP), to share information on malicious cyber campaigns. Good idea, especially since they may detect such campaigns in their commercial environments as well. Same disincentives apply as above.
The EO requires federal agencies using cloud services to adopt Zero Trust Architecture "as practicable". Also a good idea, and (if I am to be honest) something I haven't been that great about in some of my own work. I need to do better, and so does the U.S. Government.
There is a section on the need for vendors that sell into the federal space to use a secure software development environment. It recommended such actions as administratively separate build environments, and automated tools to demonstrate conformance to secure development processes. There was a lot of text about the need for products to provide a verifiable software bill of materials (SBOM). Keep in mind this was written back in May of this year, months before the Log4J vulnerability came to light. If software products in use today that depend on Log4J had such an SBOM, a lot of IT folks might be having a much more relaxed Christmas holiday.
Really an eye opener for me: there is a section proposing a cybersecurity labeling standard for consumer internet-connected (i.e. Internet of Things) devices. I very much look forward to seeing what happens with this. As a cybersecurity engineer friend of mine quips: "the 'S' in 'IoT' stands for 'Security'". I confess to still be grappling with security concerns - and the tradeoff between security and real-time behavior - in my own IoT projects.
Most unexpected: a long section explaining the use and value of system log files. Preaching to the choir, President Biden. It requires federal agencies and their IT service providers to save such logs in a secure manner, and to periodically verify the logs against hashes to insure they haven't been modified. Such logs are crucial for post-hoc analysis of lots of stuff, not just malicious cyber incidents.
The EO contains the usual caveats and exceptions for the Department of Defense and the Intelligence Community, but at the same time requires cooperation and leadership across the DoD and IC for this effort.
Several requirements mention the use of automated software tools to audit, verify, and analyze the security of government IT systems. This is going to attract a lot of tool vendor attention. It will be interesting to see how those vendors address this, since the tools themselves - which are likely to be large and complex - will also be recursively subject to these same requirements. (I find myself reminiscing about the Gödel Incompleteness Theorems from graduate school.)
I still think the major impact of this will be more revenue for the small handful of ginormous prime contractors in the defense space. But I'd like to believe it's a step in the right direction.
In "Unintended Consequences of the Information Economy" (2014) I cited an article in Foreign Affairs (2014), the journal of the Council on Foreign Relations, by former Deputy Secretary of Defense William Lynn. He talked in part about how companies in the technology sector typically invest far more of their revenue in research and development than do the handful of prime defense contractors in the United States.
What I didn't mention is how we arrived at the situation we currently find ourselves in: with just handful of big prime defense contractors.
In 1993, during the Clinton administration, then-Deputy Secretary of Defense William Perry convened defense industry executives into a meeting that came to be called "The Last Supper". He informed them that due to a huge reduction in the defense budget, there would have to be a consolidation of the defense industry.
Perry's warnings helped set off one of the fastest transformations of any modern U.S. industry, as about a dozen leading American military contractors folded into only four. And soon it's likely only three will remain, with Lockheed Martin Corp.'s announcement yesterday that it plans to buy Northrop Grumman Corp. for $11.6 billion.
The unintended side-effect of the consolidation of the defense industry into just a handful of prime contractors was that there is now far less competition in the defense sector. If the Pentagon wants to buy a new major weapons system, there may only be a single contractor capable of delivering it.
Since this happened, the U.S. Departments of Defense and Justice and the Federal Trade Commission have tried to reverse this process by opposing further mergers in the defense industry.
John Deutch, also a former Deputy Secretary of Defense as well as Director of Central Intelligence, argued, in "Consolidation of the U.S. Defense Industrial Base", published by the Defense Acquisition University's Acquisition Review Quarterly (2001), that the consolidation also led to far less stability in the companies that did survive this process
In the 1993–1998 period of euphoria, defense companies experienced significant increases in equity prices based on the expectation of revenue growth and margin improvement from cost savings. In 1998, the outlook for the industry began to darken for several reasons. First, DoD reversed the consolidation policy. Second, expected cost savings were not shared with the companies, and hence margins were squeezed, especially from increasing interest payments on debt required to fund acquisitions. Third, defense companies making acquisitions were overly optimistic about the expected growth in top-line revenues from DoD, foreign military sales, and commercial spin-offs of defense technology. The anticipated increase in defense outlays had not materialized.
Finally, some key companies found it difficult to manage their expanded enterprises effectively in all respects and to meet their optimistic financial targets. The capital markets quickly shifted to more glamorous (at that time) dot.com and high-tech stocks not associated with defense.
My tiny one-man corporation has done its share of government contracting over the years, but always as a subcontractor to a far larger organization that had all the infrastructure, people, and processes in place to deal with the federal bureaucracy. The overhead involved is a significant barrier to entry for smaller organizations. And, remarkably, to larger organizations.
In my original article cited above, I related the story of Boston Dynamics, the spin-off of MIT that designs the human- and dog-shaped robots we all watch on YouTube. After the Defense Advanced Research Projects Agency (DARPA) poured a bunch of funding into the company, it was bought by Google in 2013, who basically said “thanks, but no thanks” to any further DoD involvement. Google went on to sell Boston Dynamics to a Japanese company, which in turn sold it to a South Korean company. All that government funding resulted in intellectual property that didn’t even stay in the United States, much less in the DoD. Many large tech firms have big revenue streams that for the most part don’t rely on the U.S. government; there are easier ways to make (lots more) money in the commercial sector.
This leaves much of the technology needs of the U.S. government in the hands of just a few big prime defense contractors.
Uh oh. Do you sell to the US government? Since they buy pretty much everything, pretty much everyone does. A new executive order re security will make our lives much, much harder. Though the details are still being fleshed out, a pretty good overview here will raise your blood pressure.
Jack references an article by a vendor who is, of course, trying to sell you something, but is none the less a pretty good overview of the EO. From that sales pitch:
This EO directs these agencies to develop new security requirements for software vendors selling into the U.S. government. These requirements will be incorporated into federal contracts for commercial software and hardware with the intent of imposing “more rigorous and predictable mechanisms for ensuring that products function securely, and as intended.” This is a monumental shift that will have an immediate impact on global software development processes and lifecycles.
In addition to a host of new information and operational security measures that government agencies need to implement, the new order establishes a robust approach to supply chain security. The new requirements will include security testing throughout the development process as well as a Software Bill of Materials (SBOM) to address security issues in open source components.
I expect this EO to be a huge boon for the few existing big prime defense contractors, while preventing the small-to-medium, and even large, tech companies from participating in providing innovative technology solutions to the federal government.
As both a software engineer and a taxpayer with many decades of experience doing both, I have very mixed feelings about this. I can appreciate the need to make sure that our tax dollars aren’t wasted, that expenditures are all accounted for, and that the products our government purchases are reliable and secure. But I feel pretty confident in predicting that it will mostly mean that giants like Raytheon and Lockheed-Martin will do well.
I'm going to make a certain subset of my readership’ eyes widen and their ears perk up: the largest stock price that the NASDAQ stock exchange software can represent is $429,496.7295.
See? I wasn't wrong, was I? Many of you are laughing.
So now we know that the NASDAQ software represents a per share stock price as a 32-bit unsigned integer number in units of one-hundredths of a cent. If we convert the $429,496.7295 into units of one-hundredths of a cent (or ten-thousandths of a dollar), we get 4,294,967,295 (or 0xFFFFFFFF in hexadecimal, for those of you into that sort of thing). That value equals 232-1, which is the largest unsigned integer number you can fit in thirty-two bits. Add just one to this value and you get 4,294,967,296 or 0x100000000, which requires thirty-three bits to represent in binary, too large to fit into thirty-two bits. The result rolls over back to 0, the value in the lower-order thirty-bits.
This is just another example like the Y2K issue, or the UNIX epoch issue, what my embedded colleagues and I have generically referred to as the counter rollover bug. I have encountered this class of bug many times in my career, and written about its occurrence more than once. (See the bibliography below.)
The problem was revealed when the price of one Class A share of Warren Buffet's company Berkshire Hathaway started trading at $421,000. NASDAQ is rushing to complete a software upgrade, hoping to get it tested and installed before the price goes much higher.
This problem affects even those stocks (like Berkshire Hathaway) that are traded on other exchanges. NASDAQ has a stock price quoting service that reports on stocks that they themselves don't trade. In fact (I had to look this up) NASDAQ originally stood for "National Association of Securities Dealers Automated Quotations" and was merely a quotation service.
Despite the fact that I rate off the scale on introversion on every personality test I've ever taken, I am skeptical about the the Work From Home and Remote Learning trends. As necessary as they are during these Plague Times, I don't think we have any idea of the long term effects on our corporate culture, our productivity, our innovation, or on our and our children's emotional maturity and communications skills. We are a species that evolved to live and work in tribes.
This morning I read two articles that I liked on this topic.
In "What a Year of WFH Has Done to Our Relationships at Work" (Baym et al., HBR, 2021-03-22), three Microsoft researchers analyze ginormous datasets to determine how communication between team members have changed. Hint: they've become much more siloed.
In "I've lost my conversational mojo - can I relearn the art of small talk?" (Samadder, The Guardian, 2021-04-17), actor and columnist Rhik Samadder talks - socially distantly - to experts in the art of small talk, including to the neuroscientist for which the "Dunbar Number" is named. Upshot: the experts think we'll adjust back to being social again more readily than we might think.
I am concerned about limiting our interpersonal communications to those channels moderated by technology. It's not just about the loss of body language and other social cues. Or the lack of the productive backchannel that is the spontaneous hallway conversation. Or the magic that happens when you get a few smart people in the same room in front of a whiteboard.
It's also about the way in which I turned from being a socially awkward introvert to being - I am told, anyway - skilled at collaborating, teaching, public speaking, and giving executive briefings (while still being a little socially awkward). Being a strong introvert - some might even say a nerd - those skills didn't come naturally to me; they were learned through years of hard-won, and sometimes even painful, experience. Experience that we are eliminating in the WFH and RL world.
I hear a lot of folks talk about how much they prefer WFH and RL. And a lot of those preferences are totally legitimate. But for some of those folks, the strong introverts, I fear that they prefer it because it gives them an excuse not to grow and learn and exercise important social skills.
I also fear this is just another facet of late-stage capitalism, in the form of another cost - the cost of providing adequate infrastructure - that corporations can push off onto their employees, while the resulting hidden expense to the organization remains largely unaccounted for.
I don't think we appreciate what we're giving up. And we have little understanding for the possible long term consequences.
Update (2021-04-22)
Laurie Kenley, a cloud security wrangler, made these insightful remarks in another forum, and kindly gave me permission to reproduce them here verbatim.
I am off the scales in extroversion and I have been working from home for 2 1/2 years. I had to re-create my life around the fact that I would not be getting social interaction in my job well before the pandemic. I had it all figured out. And when the plague hit, all of that collapsed. It took a lot of figuring out how to be OK. Not great but OK.
One thing I will say that has been “better“ during the pandemic as a remote worker, is that everyone is remote now and it’s a level playing field. I have been able to be more effective and more plugged in to my coworkers than ever before in this remote job. To use a Hamilton reference, "the room where it happens" is now a virtual room. It has democratized decision making in a way I don't necessarily expect to last in the coming months.
Ghidra is an open source graphical tool produced by the U.S. National Security Agency (NSA) to analyze binary (compiled) software images for a wide variety of hardware targets and compiler platforms. Amongst its many capabilities are generating a disassembly listing and (remarkably) generating a decompiled listing back into C. This latter case requires that the tool recognize idiomatic instruction sequences produced by common compilers like GNU C, as well as deal with some special cases in which assembler code is inserted inline by the C developer, e.g. for memory barriers, low level synchronization primitives, and accessing special hardware registers.
The NSA released version 9.0 of Ghidra to the public just about two years ago. I wrote a couple of articles (see references below) here about using it to reverse engineer compiled code from my Diminuto, Hazer, and Scattergun projects. I did find a couple of bugs - multiple symbol tables in shared objects confusing the disassembler, and inserted memory barrier instructions confusing the decompiler - reported them, and got useful feedback from one of the developers.
Yesterday I installed the latest public release of Ghidra, 9.2.2, and tried two of the specific cases that were problematic that I wrote about in my two blog articles. Casual perusal of the Ghidra 9.2.2 disassembled and decompiled output for ARM7 binaries suggests both of these issues have been resolved. I updated both articles with remarks to this effect, and included screenshots of the updated output.
Reverse engineering has a lot more applications than just cybersecurity. Analyzing deliberate malware isn't typically my area; but debugging proprietary embedded software, and integrating my and my clients' new code with legacy systems, is an integral part of what I do for a living. Tools like this can be crucial for dealing with undocumented or under documented legacy systems. Reverse engineering tools like Ghidra should be in the toolkits of embedded and other low level systems developers.
My Hazer project (com-diag-hazer) - the basis for all my GPS/GNSS work that I've written about - depends mightily on my Diminuto project (com-diag-diminuto) - my C systems programming library and framework - for its infrastructure. Testing some of the Hazer features finally got complicated enough that I built a dedicated test fixture for that project, just as I had to build a little test fixture for Diminuto that I described in Where the Silicon Means the Road.
While Hazer's gpstool utility supports a wide variety of GPS/GNSS receivers, the one I chose for the test fixture is a SparkFun board equipped with a u-blox NEO M9N device. Here is some gpstool output generated while exercising the M9N.
I chose the M9N because it can receive and process transmissions from the satellite constellations of the U.S. GPS (a.k.a. NAVSTAR) system, the Russian GLONASS system, the European Galileo system, and the Chinese BeiDou 2 (a.k.a. COMPASS) system simultaneously. This tests more code paths in the underlying Hazer library and in gpstool.
The M9N is powered by a USB C connection to a dedicated Raspberry Pi 4B running Raspberry Pi OS, the Debian-based version of GNU/Linux formerly known as Raspbian. The USB connection is also the serial communications channel between the Pi and the M9N. The Pi runs headless; when necessary, I ssh into it from my desktop Mac and use the command line interface (although in a pinch, I have connected up a display, keyboard, and mouse to the Pi, or even attached a USB-to-serial adapter to its console port pins).
You can see the SMA Radio Frequency (RF) connector emerging from the container, where it connects to the coaxial cable of the GNSS antenna used by the M9N. The small multi-band active patch antenna sits on the top shelf of my workbench within view of the window.
You can also see a green wire and a blue wire that run from the M9N container to the Raspberry Pi.
The green wire connects the 1PPS ("one pulse per second") signal from the M9N to a General Purpose Input/Output (GPIO) pin on the Raspberry Pi. 1PPS is a standard precision timing signal derived from the GNSS solution by the receiver (although not all of them export it, and when they do, the mechanism varies). I make use of 1PPS in all of my GNSS-disciplined Network Time Protocol (NTP) micro servers that I've written about previously, including the one that incorporates a chip-scale cesium atomic clock. When gpstool is configured to monitor the 1PPS signal, it uses Diminuto's GPIO feature to interrogate the input GPIO pin using the select(2) system call inside a dedicated POSIX thread (which is also a Diminuto feature).
The blue wire connects an second, output, GPIO pin on the Raspberry Pi to an LED in the little container where the M9N is mounted. When gpstool monitors 1PPS, it can be configured for the thread to strobe the second GPIO pin to follow the 1PPS signal. This is not just a test of Hazer and gpstool, but a test of Diminuto's GPIO feature as well.
My hardware engineer colleagues will confirm that I'm not a hardware guy by any stretch of the imagination. But hacking together these little hardware test fixtures gives me peace of mind. As long as I see that LED blinking at 1Hz, I know that, while my code is not perfect, it is at least sane.
When using the Tesorochoosedataset/routemap feature - which generates a static map using the Leaflet library for OpenStreetMap - you can draw multiple routes on a single map just by using the Choose File menu more than once without refreshing the web page.
The default properties used by Tesoro for route maps gives the route a color of red and a weight (pixel width) of 3.0, where these are both properties supported by the Leaflet polyline API. This is what you saw in the images in A Static Route Map Display Using OpenStreetMap.
You can override this for all routes on the same map by specifying Leaflet polyline options (including color, weight, and others) as keyword=value pairs in URL query parameters. When you do this, your URL will look something like this example, which specifies a yellow polyline with a weight of 3.
You can also specify options for a specific route by including the Leaflet polyline options as properties in the original dataset, just as its PATH property contains the array of coordinate pairs. When you do this, your dataset will look something like this example (but probably a lot longer), which specifies a blue polyline with a weight of 6.
{
"color": "blue",
"weight": 6.0,
"PATH": [
[ 39.7943158, -105.1533988 ]
, [ 39.7943148, -105.1533981 ]
, [ 39.7943140, -105.1533973 ]
, [ 39.7943136, -105.1533960 ]
]
}
You can use both together, generating multiple polylines on the same map, some with your modified default options, some with more specific options.
Below is a map with two routes, one yellow, one blue, each defined with its own dataset, each imported by its own Choose Dataset dialog. The yellow route was colored using the URL query parameters which changed the default color from red to yellow. The blue route was specified by a color property inside the dataset itself for blue.
The properties in the dataset will override the URL query properties. The order in which you choose the datasets may also be important for your specific application, since successive routes will be rendered on top of prior routes. Changing the weight you use for each route can improve the readability of a multi-route map. Changing the color property of a route can also make it more readable on a specific map, depending on the background colors used in the map.
Sometimes I need a moving map display in real-time to track my projects at they move around in the field. Sometimes I want to playback a stored dataset of geolocation coordinates. And sometimes I want to see a static route map that shows the path a project took in the field. This latest addition to my Tesoro project does that. As before, it uses the Leaflet client-side JavaScript library and an OpenStreetMap tile server.
Here are a couple of static route maps generated from geolocation datasets collected from field testing. (You can click on either one to see a larger version.)
This new feature adds another web page, choosedataset.html, and another client-side JavaScript program, routemap.js, to the project. As with the moving map display, occasionally useful information is displayed in the browser's JavaScript log, as shown in the second image.
(Blogger kind of sucks for rendering code. Each example below in the monospace font is intended to be a single line.)
My Hazer C-based GNSS software stores geolocation data in a Comma Separated Value (CSV) format that makes it simple to import into spreadsheets and to post process for other uses. Each line of the CSV dataset looks like this.
My moving map display described in A Moving Map Display Using OpenStreetMap and subsequent articles steers the moving map, in real-time or in playback, using JSON datagrams, each datagram containing the coordinates for the next point. Each individual datagram looks like this.
The dataset used by the static route map is a JSON object containing an array of latitude and longitude coordinates. All of the points on the route are contained in a single array that is imported by the new software and stored in memory for processing. The dataset looks like this (although is typically much larger).
which can be used directly by the Tesoro map software.
Because the JSON object for the static route map has to all be stored in memory for processing by the Leaflet library, there is a limit to how many points you can render at a time. I ran into the same issue using the XML-based Keyhole Markup Language (KML) when rendering routes with Google Earth. But the second image above rendered a dataset of more than 8500 data points, collected from a field test almost two and a half hours long, with no discernible delay.
But for those really large datasets, the Hazer csvdataset script takes an optional modulo argument to sample the incoming CSV data. The Hazer gpstool utility stores CSV records at approximately 1Hz. So an argument of 10 would sample every tenth data point, capturing the target location about every ten seconds. But no matter the argument value, the first and last data points are included so that the start and end of the route is always rendered.
As is well known, cats are the natural enemies of vampires. This has been clearly established by overwhelming empirical evidence. This is because cats recognize that vampires can take the form of bats, which are just a kind of flying mouse (German: "fledermaus" or "flitter mouse"). Also, cats are naturally aggressive towards any creature that tries to unseat them as the apex predator. Finally, cats must challenge anything that threatens the cushy situation cats have created for themselves with their human domestic servants, whom vampires consider to be merely livestock. [Ref: J. A. Lindqvist, Let the Right One In ("Låt den rätte komma in"), St. Martin's Griffin, 2004]
Vampires are repelled by the Christian cross, not due to its religious symbolism, but because vampires have a cognitive bias against right angles. Again, there is a wealth of research about this, the most widely accepted hypothesis being that vampires predate the evolution of humans by hundreds of thousands of years, having evolved long long before our distant ancestors introduced artifacts built with right angles, angles which typically do not appear in nature. Vampire brains never evolved the ability to deal with right angles, which may also explain why humans prefer Euclidian architecture, as a form of defense. [Ref: P. Watts, Blindsight, Tor, 2006]
This is why cats are attracted to boxes. Or even squares drawn on the ground. They feel safe from vampires, their natural enemies, when inside boxes because they know that the vampires will be repelled by the right angles found in boxes. The fact that cats began cohabiting with humans when we began building structures incorporating right angles cannot be a coincidence.
This startling and enlightening revelation came to me this morning during an argument with one of my Beloved Feline Overlords while I was trying to break down some old cardboard boxes for recycling - an argument my BFO, of course, won.
One of the advantages of implementing tools as web applications is that it opens the possibility of running them on a wide variety of platforms, with browsers that support JavaScript and HTML5, with little or no additional effort. I'm a little embarrassed to admit that it just recently occurred to me that I should be able to run my OpenStreetMap (OSM) Moving Map web app on my iPad and iPhone. So I did. It worked fine.
Here is a screen snapshot from my iPad using Safari.
Here is one from my iPhone 7, also using Safari.
And for good measure, here is a screenshot from my Google Pixel 4 development phone using Chrome under Android 11. It worked fine too.
I routinely run the web app on Safari, Firefox, and Chrome on my desktop Mac or my Mac laptop, and on Firefox and Chrome on an x86_64 Linux server. Now I can add genuine mobile devices to that list.
But wait! There's more!
I described in prior articles about this project, code-named Tesoro, how the server-side JavaScript program channel.js serves as a conduit between my Hazer C-based GPS software in the field, which forwards geolocation data in JSON over UDP, and my web application whose OSM-based moving map is steered by that incoming data stream. Alas, channel.js only services a single data source at a time (although you can run several instances simultaneously using different UDP port numbers).
Tesoro now includes another server-side JavaScript program, controller.js, that can handle an arbitrary number of geolocation data sources concurrently, all using the same UDP port number, and provide an individual URL for each one for the Tesoro web application. I have an instance of controller.js executing now on one of the Raspberry Pis that runs 24x7 at the Palatial Overclock Estate, serving as the sink for any geolocation project in the field (or for a playback of the dataset collected from any such project), and as the source of that same data for any moving map displays on my internal network.
The moving map display I demonstrated in the forty-five minute video in A Moving Map Display Using OpenStreetMap (2021) was the result of playing back a dataset I had collected in 2020 during a test of a u-blox UBX-NEO-M8U, a relatively complex piece of kit that included not only a Global Navigation Satellite System (GNSS) receiver but also an integrated Inertial Measurement Unit (IMU). I wanted to capture a moving map video in real-time just to remind myself that it could be done, so this morning I did just that.
The Overview
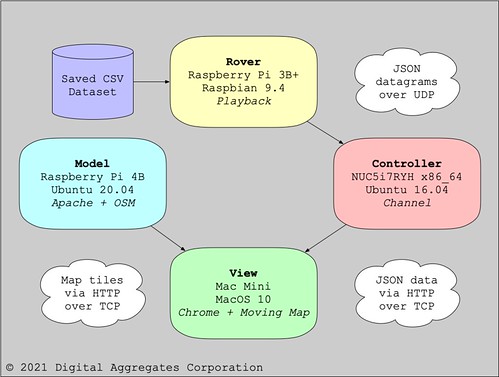
You might recall from that prior article, my implementation consists of four components.
The Rover is either a GNSS receiver connected to a computer running my Hazergpstool software to collect geolocation data in real-time, or a computer playing back such a dataset.
The Model is an OpenStreetMap (OSM) tile server that serves up graphical map segments and associated metadata via HTTP requests over TCP.
The View is your favorite modern web browser supporting JavaScript and HTML5 that renders the moving map using tiles fetched from the Model as it is steered by the Controller.
The Controller is a conduit that captures the datagrams of JSON data transmitted by the Rover over UDP and makes them available to the rest of the system via HTTP requests over TCP.
The Model, View, and Controller are all part my Tesoro project.
The Good Stuff
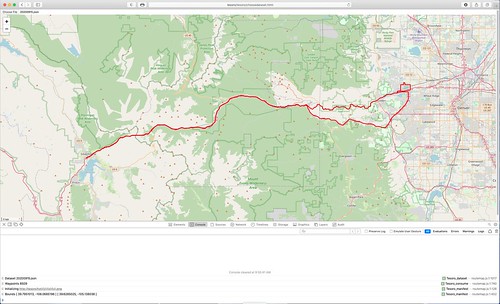
We'll start off with today's fifteen minute (14:49) video, captured on a display at my home base while I drove my Subaru WRX equipped with the Rover around the neighborhood. Feel free to skip around. (If the video doesn't show up for you, you can find it on YouTube. For best results, open the video up in a larger window, and select the High Definition version.)
The Test Setup
The Model was the same Raspberry Pi as before, running the OSM software stack as an Apache web application.
The View was my desktop Mac Mini with a Cinema Display, using QuickTime to capture the video from the Safari web browser running the Tesoro client-side movingmap JavaScript program.
The Controller was the Tesoro channel server-side JavaScript program running under Node.js on another Raspberry Pi. It is the same RPi I use as a Real-Time Kinematic (RTK) corrections server for Differential GNSS (DGNSS) for my Tumbleweed project.
The Rover consisted of a relatively inexpensive USB-connected receiver, a GlobalSat BU-353S4-5Hz, based on a SiRF Star IV chipset. (SiRF is a division of mobile phone chip maker Qualcomm). It was connected to a GPD MicroPC running Hazer's gpstool under Ubuntu MATE. The tiny palmtop computer was equipped with an external NovAtel MiFi USB730L LTE modem that it used to transmit its JSON datagrams containing geolocation data back to home base.
Here is the Rover sitting in the WRX during the test; the GPS receiver is at the far left on a mount on the dashboard, and the PC is sitting on the passenger seat at the far right with the LTE modem visible on its left side.
Here's a close up of the BU-353S4-5Hz receiver in my lab. The little USB dongle is not much larger than a wristwatch face, and includes the GPS receiver, the active (amplified) patch antenna, and the USB interface which provides both connectivity and power. It's magnetically mounted on a steel plate that serves as a ground plane, a reflective surface for GPS radio waves.
The GPD MicroPC, shown below on my lap bench with the LTE modem attached on its left side, is basically a pocket-sized ruggedized industrial PC. Although I don't do any touch typing on its chicklet keyboard, I really like the fact that the little Intel Celeron-equipped palmtop incorporates a lot of useful interfaces, including WiFi, an RJ45 Ethernet jack, and an RS232 serial port with a DB9 connector.
UDP vs. TCP
If you watch the video, and pay attention to the JavaScript console at the bottom, you will notice that the movingmap script occasionally reports missing JSON datagrams. This is typical of my experience in the field using LTE modems and the best effort User Datagram Protocol (UDP) to transmit geolocation updates to the home base. This causes the moving map display to briefly stall and then jump forward as it catches up to the real-time data.
As you might expect, using the guaranteed delivery Transmission Control Protocol (TCP) instead of UDP solves this problem. And indeed, my initial implementation years ago used TCP. But what I found during these kinds of real-time visualizations, especially in locations with spotty cellular reception, is that the display could lag many seconds behind real-time as the TCP/IP stack retransmitted lost packets. And once behind, it never caught up. In fact, it sometimes got progressively worse. It was far better to have the map pointer jump forward than to permanently and increasingly lag behind what was happening in meat-space.
I talked about this at length in Better Never Than Late (2017): in this particular real-time application, it is better to lose packets, or drop packets that arrive out of order, than it is to wait for the network stack to ensure perfect reliability. Besides, my Hazer software saves all the geolocation information on the Rover as a dataset of Comma Separated Values (CSV). So at worst, you can play back the dataset with perfect fidelity when the Rover returns to home base.
(Note: edited several times for corrections and clarity.)
Google Maps is a treasure. Hardly a day goes by that I don't use it. If I see a news item that interests me that includes an address, or even just a neighborhood, chances are good I'll be looking it up. By the time Mrs. Overclock and I got to Helsinki Finland to attend the World Science Fiction Convention in 2017, I had already "walked" all around the neighborhood of our hotel using Street View.
But although using Google Maps this way for me is free, it is a costly commercial product to develop and support. The maps have to be continuously updated with corrections and changes. The Street View images are routinely laboriously updated and ground truth established by humans driving extensively instrumented vehicles. The Satellite View images are updated frequently enough that I am often surprised to find that the season or the landscaping has changed since the last time I looked at my own neighborhood. It can't be cheap. Google supports this "free" service through a combination of fees for businesses that choose to advertise on this platform, and by licensing its use for products that use this platform for their own mapping needs.
By now, anyone reading my blog has come to realize that I have had a long running, broad, and deep, personal effort at writing applications using the U.S. Global Positioning System (GPS), and more broadly, other Global Navigation Satellite Systems (GNSS). More recently I branched out to include Inertial Measurement Units (IMU). This is part of my Hazer project, the source code repository for which can be found on GitHub. I am understandably interested in mapping the results of my tests, either in real-time or as part of my post-test analysis. Google Maps would have been ideal for this, but the price tag was a little high for something that amounts to an intensive hobby.
In my article Better Never Than Late (2017), I tracked a mobile GPS unit in my car by transmitting its geolocation data back to my home office via an LTE modem, to be mapped in real-time using Google Earth, an application program that provides a programmatic way to use satellite imagery. This worked great; but sometime between 2017 and 2018 the capability to do this in real-time with Google Earth stopped working. I was still able to do the post-test mapping by importing the data into Google Earth in Keyhole Markup Language (KML) form, as illustrated in my article Dead Reckoning(2020). But I wanted a solution for a real-time moving map display.
Recently I became aware of OpenStreetMap (OSM), an open-data, community-driven, project to provide an alternative to Google Maps for exactly the kind of real-time mapping in which I was interested. Thus was born another project, Tesoro, also hosted on GitHub, with the goal of incorporating OSM with Hazer to create a real-time moving map display.
Demonstration
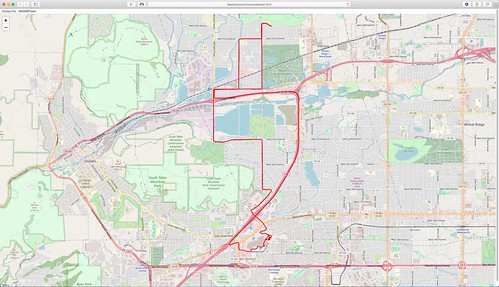
Before I get to the nuts and bolts of Tesoro and OSM, let's go right to the good stuff: a video of the moving map display that I implemented. This is a forty-five minute (45:47) video, so no one (not even me) is going to want to watch all of it. But it's fun to skip around and watch different parts. For best results, watch this video in a separate YouTube window, and if your user interface supports it (not all do), choose the High Definition option so you can read the labels on the map. Opening it up into Full Screen mode helps too. Or be prepared to do a lot of squinting. (If the video below doesn't show up for you, try this link to the video on YouTube.)
This test used a playback of geolocation data I collected during IMU testing conducted on 2020-09-17. The playback mechanism uses the same UDP-based networking to feed the Hazer data stream to Tesoro that I have used previously in the field, so I would expect it to work almost as well with a real-time feed, subject to the occasional data loss I witnessed using LTE modems. (In Better Never Than Late I make the case as to why UDP, and not TCP, is the correct internet protocol to use for this. Alas, an efficient and easy to use method of encrypting and authenticating UDP traffic - while maintaining the characteristics of UDP that I find important - is in my opinion an unsolved problem.)
Overview
Tesoro broadly consists of four components: the Rover, the Model, the View, and the Controller. Web developers will recognize the Model-View-Controller (MVC) nomenclature used to describe a design pattern for interactive applications. GNSS developers will recognize Rover as the mobile portion of a Differential GNSS (DGNSS) system. (As always, you can click on any image to see a larger version.)
Although most of my development of Tesoro was done by running all of these components on a single computer, that didn't reflect how I expect the system to be used in real life. So for the video above, I split the components onto four different computers.
The Rover
The Rover plays the role of the component in the field, running the Hazer gpstool application and forwarding the resulting geolocation data via UDP back to the home base. For this test, the Rover was one of my Raspberry Pi 3B+ development machines running a version of the Debian Linux distro called Raspberry Pi OS (formerly called Raspbian).
gpstool saves geolocation data in a Comma Separated Value (CSV) format so it can be easily imported into a spreadsheet. The Hazer csvmeter script reads the stored CSV data and meters it out at approximately the same rate - typically 1Hz - as it was originally generated by the GNSS receiver under test. The output of csvmeter is piped to the Hazer csv2dgm utility that trivially converts it into JavaScript Object Notation (JSON) - the standard data serialization format used by JavaScript and lots of other applications because it is far simpler than eXtensible Markup Language (XML) - and sends the resulting datagram on its way.
The Rover can be tested by using the Linux/GNU utility socat to receive the datagrams and display them on the console.
The Model
The Model (short for Data Model) provides the database of map data used by the moving map display. The Model is an OpenStreetMap tile server, a server-side web application and database that provides tiles - graphical map segments - via Hyper Text Transfer Protocol (HTTP). It is hosted on a Raspberry Pi 4B computer with a two terabyte (2TB) Solid State Disk (SSD) in addition to its own root file system on a microSDcard.
This tiny Single Board Computer (SBC) runs, not the typical Raspbian, but a full blown version of Ubuntu, another Debian-based Linux distro. I chose Ubuntu over the usual Raspbian that I run on the other ten Raspberry Pis that run 24x7 at the Palatial Overclock Estate because the OSM stack was known to work under Ubuntu. Could it run under Raspbian? Got me. When I found out that there were instructions for installing OSM under Ubuntu 20.04, and there was a version of Ubuntu 20.04 that could be installed on the Raspberry Pi 4B, I looked no further. Installing Ubuntu, then the entire OSM stack, then the map data for North America, then building the map database, on the Raspberry Pi was a relatively simple but time-consuming process.
I was careful to keep the map dataset (which is very large) and the Postgres database (which is very active) on the SSD. Given that just today I saw an ad for a one terabyte (1TB) microSDcard, it might be possible to implement a tile server without the SSD.
The Model can be tested by issuing an appropriate HTTP request from a browser or the Linux/GNU command line utility wget and seeing what comes back.
The Controller
The Controller provides the data stream that steers the moving map. It is implemented by channel, a small server-side JavaScript program I wrote that stands up a microscopic HTTP server. The channel receives the JSON datagrams from the Rover via UDP and caches the most recent one. When channel receives an HTTP request of any kind (it's not picky) over TCP, it responds by replying with the latest JSON datagram.
The channel is merely the conduit through which the JSON datagrams from the Rover can be received by the client-side web browser a.k.a. the View. Non-web developers may be surprised (I was) at how difficult this simple requirement is to solve. Browser security is an ever tightening chain of rules and sandboxing designed to keep malicious web sites from stealing your identity or infecting your laptop with malware. A lot of solutions you might take for granted as being feasible are actually deliberately impossible.
JavaScript programs running on the server-side under the standard Node.js compiler/interpreter have no such restrictions, however. I ran the channel JavaScript program on one of my x86_64 Ubuntu development systems, but any Linux/GNU system running Node.js would do.
The Controller can be tested by running channel and then making a web request using a browser or wget.
The View
The View is the visualization engine of Tesoro. It consists of a lot of client-side JavaScript code running inside of the web browser of your choice, being steered by the JSON it periodically fetches via HTTP from the Controller, and then rendering the appropriate map segments it requests from the Model. The View is implemented by a combination of Hyper Text Markup Language (HTML) files that download and run my movingmap JavaScript program. movingmap is built on top of Leaflet (1.7.1), a widely used JavaScript library that provides a client-side API to OSM. It is Leaflet that does all of the heavy lifting with OSM.
The View client-side HTML and JavaScript code (including Leaflet) are hosted on the Model, the OSM tile server, as just another Apache web site application. They are downloaded and executed inside the web browser on whatever computer the browser is running on. You can probably run the View on any modern web browser that supports JavaScript. The video above was recorded with QuickTime using the Google Chrome browser running on my desktop Apple Mac mini running macOS 10 with an Apple Cinema Display. But I have also run the View with Firefox on an x86_64 Ubuntu system, and with both Firefox and Safari on the same Mac.
Tesoro includes several HTML web pages that can be used to incrementally test the View and the rest of the software stack, first displaying a static map at a fixed location, then a static map whose latitude and longitude are specified as a query in the Uniform Resource Locator (URL), then finally as dynamic moving map display being steered by a user-specified channel.
Details
This is an image of the Raspberry Pi that is the OpenStreetMap tile server (center). It resides in an old stereo rack alongside my web server (left), and a Real-Time Kinematic (RTK) update server (right) that is part of my DGNSS project.
This is the console output of the Rover's csv2dgm utility, which is written in C and is part of Hazer. When debugging output is enabled, csv2dgm displays both the incoming CSV record and the outgoing JSON datagram.
Although for this example I was playing back a dataset of CSV records previously recorded as part of an actual field test, the same csv2dgm utility is used in the script that runs on the Rover in the field; this output is an easy way to verify that the Rover is generating datagrams before deploying it.
The Controller's channel JavaScript program that runs under Node.js is pretty chatty as well. Every time it receives a datagram over UDP, it displays its JSON payload as well as the sender from which it was received. Every time the View (or anyone else) issues an HTTP request over TCP, the program displays the requestor and the JSON it was sent.
This output is especially useful since it can be saved as a permanent record on the local computer on which channel runs, independent on to whether the CSV dataset saved on the Rover in the field is eventually recovered.
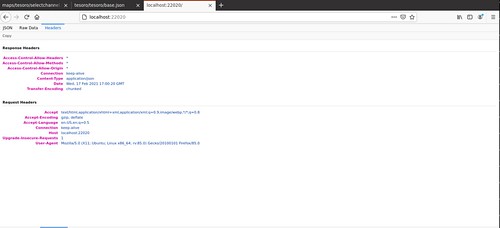
All three of the web browsers I tested with - Chrome, Firefox, and Safari - have very useful debugging tools built in. In this screen shot from the video above, you can see the moving map on the left, and an optional console log on the right. Tesoro's movingmap client-side JavaScript program makes use of this log to reveal what it is doing. All three browsers have a console log like this, variously called "JavaScript Console", "Web Console", or a "Console" tab on a "Developer Tools" window.
All three browsers also have tools to examine the headers used in the HTTP protocol. This is useful for debugging all three components, Model, View, and Controller, since all use HTTP.
The README file for the Tesoro repository on GitHub has links to the pages I used to learn how to install Ubuntu on the Raspberry Pi, to install the OSM software stack, to download the map data, and to build the Postgres database, all on the Model tile server.
In addition, the repository includes a text file of mostly unstructured notes that might be useful if you get stuck trying to reproduce my results. Be aware, though, that not all of the notes led to something I actually used or did; some were dead ends.
Conclusions
I'm a little surprised how well this project worked, mostly because I wasn't a web developer when I started it. I'm not a web developer now, either. JavaScript will not be appearing on my LinkedIn profile.
But thanks to having hacked other developer's JavaScript on various paying gigs that had a web component, and to the wealth of documentation I found online, I was able - as usual - to learn from people smarter than myself.
(Note: edited several times for corrections and clarity.)
The human brain is so wired for detecting patterns, our desire for order in a universe ruled by chaotic behavior so great, our need for a narrative so ingrained, that we detect patterns and create a narrative from them that implies order, even when there is no actual story to be told. It is both our greatest weakness and our greatest strength. Which is why we need to stick to the scientific method and be evidence based. That is a kind of narrative generation too, but it is a story we reject when it no longer matches the facts at hand. Many synthesized narratives imply order when reality may be nothing more than rational but uncorrelated actors responding similarly to a common set of incentives.
I think about time a lot. I have a cesium atomic clock "ticking" away in my living room. I've stood alongside one of the official cesium frequency references, and also the experimental ytterbium optical atomic clock, at the NIST laboratories in Boulder Colorado.
For a long time, I thought there wasn't really any such thing as time per se, only events connected by causality. After all, all of our means of measuring time have to do with counting events that occur in some naturally occurring resonator: pendulum, quartz crystal, cesium atom, etc. This is a point of view held by at least some research physicists, so it's not a completely crazy idea.
But in one of Dr. Sabine Hossenfelder's blog posts, a commenter mentioned the effects of special and general relativity on our measurement of time, in which acceleration and gravity wells, respectively, slow time down, according to those very same resonators. That comment completely changed my world view. So now I think time is a real thing, not just a measurement artifact.
Next thing to think about: why does time play a role in the large (classical physics, cosmology, etc.) but not in the very small (where it doesn't appear as a factor in the equations used by quantum physicists)?
Separately: what sometimes keeps me awake at night (really) is that there is much evidence that at both the quantum (Bell's Theorem) and cosmological ("block time" a.k.a. "block universe") level, reality appears to be super deterministic: both the past and the future are fixed, and we are just passive observers playing our roles as we move along the timeline. We can't predict the future; but we can't change it either.
You may have read by now that the online vaccine management system that the Trump administration paid US$44M for from the consulting firm Deloitte in a no-bid contract is a disaster. Riddled with bugs like making and then randomly cancelling appointments. States are giving up and cobbling together their own solutions.
About half my career has been spent doing work funded by the U.S. government, either in Big Science or in the Military and Intelligence sector. What I found the most interesting about this mess is one of the reasons Deloitte got the non-competitive contract in the first place. Did they have any experience in large scalable distributed medical computer systems? No. Infectious diseases? Nope. Vaccination programs? Not even. What they had experience in is government contracting. And the procurement systems implemented by the feds make it difficult - not to mention less profitable, compared to other work in the commercial sector - for anyone who isn't already doing government contracting to do government contracting.
I'm reminded of when Google bought Boston Dynamics. The robot company had been mostly funded by DARPA, the U.S. DoD's advanced research arm, the folks that have a track record of bringing us things like the Internet. Once Google bought Boston Dynamics, they declined to renew the DARPA contract. The DoD-related industry was surprised; I read articles in the DoD trade and national security press about this at the time. But I doubt many in the high tech industry even batted an eye. Selling to the Feds used to be a big thing. Now, not so much, compared to the global market. (Google eventually sold the company to Hyundai. Yet another bleeding edge albeit immature technology transferred to a foreign company.)
Another issue that occurs to me is how long it takes to design, develop, test, and deploy a product as big and complex as the proposed vaccine management system. Contrary, I suspect, to expectations in the White House at the time, a commercial effort of this type would take a year or two, all told. Regardless of the sales pitch from any consulting company, there is no fast path. That's why you have to anticipate this kind of need, and address it well in advance of it becoming a necessity. It's like insurance: you have to buy it before you need it, with the understanding - and the hope - that you never actually have to use it.
Back around 1995 I was a section head in the Scientific Computing Division at the National Center for Atmospheric Research (NCAR) in Boulder Colorado, a national lab sponsored by the U.S. National Science Foundation. Besides leading VIPs around on tours, at that time I was involved in helping write proposals, papers (one of which was the featured article in the Proceedings of the IEEE), patent applications, and design documents for a terabyte hierarchical Mass Storage System, the next generation of NCAR's groundbreaking data storage architecture. The existing NCAR MSS had a floor-full of offline tapes and tape drives, several robotic tape silos, and a pile of disk drives. That is what it took to feed data to NCAR's several supercomputers and to soak up the results. A terabyte was an almost unbelievable amount of storage at the time.
This morning I'm continuing to work on my latest project, which incorporates a two terabyte Solid State Disk - no moving parts - so small it would easily fit in my shirt pocket. I bought it off Amazon because our local office supply store only had the one terabyte model of the same drive, and I needed something larger. The SSD is USB attached to an equally pocket-sized US$75 Raspberry Pi 4B Single Board Computer, which also provides all of the SSD's power.
I'm a fan of Ben Thompson's business analysis blog Stratechery. It's hard to say exactly what it's about. His background (such as it is; he's actually younger than his writing and analysis would lead you to believe) is an M.B.A. from the Kellogg School and a relatively brief career in marketing and strategy. But what he writes about is far broader than that. Even if I don't agree with him, he gives me much to think about.
His latest article, "Trump and Twitter", is why he supports Twitter's blocking of President Trump. This is not the first time that he has written that social media companies have to have the following priorities, from highest to lowest:
liberalism is inviolable;
democracy must be respected;
bad policies should be opposed.
Here, liberalism isn't used here the Big-L Liberal political sense; it is used in the small-l liberal sense that we are
governed by the rule of law, and
have a guarantee of individual rights and personal liberty.
This is the way it's meant in the phrase "liberal democracy".
This is kinda like Asimov's Three Laws of Robotics: democracy only if it doesn't violate individual rights (the majority can't vote to take away someone's individual rights except in the case of the rule of law); oppose bad policies only in as much as they respect democracy and don't violate the rule of law or individual rights. And you have to remember that rule of law is the first liberal requirement.
I confess I'm still trying to decide whether I agree completely with this list of priorities; I'm inclined to say that I do, but I need to ponder the consequences of it. For example, our First Amendment rights to freedom of speech do not protect all speech (contrary to popular belief). So in fact, banning Trump from Twitter does not violate his right to freedom of speech, because speech that promotes hate, violence, and crime is not protected; that is the rule of law. Also, our First Amendment rights are regarding what our government can do, not what a company or individual can do; no one is required to provide someone a forum for their speech, protected or not (something else that people often don't understand).
The point here is the people who stormed the U. S. Capitol were following priority #3, while ignoring #2, and the "rule of law" part of #1.
I think using these three simple priorities as a kind of ethical checklist is the way I am heading. Is it complete? Probably not. But a lot of stuff other folks would want to add would actually fall under #3, opposing bad policies. The weakness in this is that you and I (and the yahoos that stormed the Capitol) may disagree what a exactly a "bad policy" is. But even as we disagree, we surely can agree that #1 and #2 come first.
Once you and I can agree on #1 and #2, we can have a civil, rational conversation about what falls under #3.
Chip Overclock® is a megalomaniacal supervillain and the secret identity, pseudonym, alter ego, and registered trademark of John Sloan, a technology product developer who specializes in very large and very small systems on the internet of interesting things: distributed, real-time, high performance, high altitude, embedded, concurrent, parallel, asynchronous, remote, close to bare metal.