("Ghidra" is the multi-headed Toho film monster whose name is probably derived from "Hydra", the many headed serpent from Greek mythology.
 |
| Photo credit: Wikipedia |
Ghidra is written in Java (it requires OpenJDK 11), Jython (an implementation of Python that runs on the Java Virtual Machine), and C++. It runs on 64-bit Windows, MacOS, and Linux platforms. It has a graphical user interface and includes a disassembler, and even more remarkably, a decompiler.
In order to represent a file of machine instructions as decompiled code - C code in my examples - the decompiler has to recognize idiomatic instruction sequences that are specific to a compiler - GNU C in my examples - and to a machine architecture - x86_64 and ARM in my case. To distinguish instruction sequences from data, the disassembler has to follow the logical flow of instruction execution, decoding successive instruction sequences, and following all possible transfers of control (jumps, branches, function calls) to new sequences. This forms a cyclic graph of control paths to determine exactly what bits are instructions and what bits are data, the latter being bits to which there is no flow of control. This is no mean feat.
(You can mouse click on any of the images to open a larger and hopefully more readable version. My fu with the Blogger platform kinda sucks at rendering code samples no matter what I try.)Here is the prototype for a function from my Diminuto library of C systems programming tools that debounces digital input signals. The application calls this function at some fixed frequency - 100Hz (every 10ms) works well for typical mechanical contact switches - and gets a 0 (unasserted) or 1 (asserted) result.
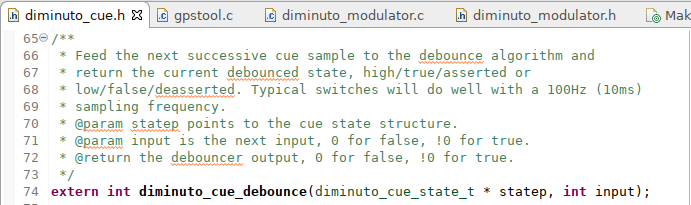
Here is its implementation. (I didn't invent this algorithm, I've just used the heck out of it. The header file for this feature lists the references from Dr. Marty and from Jack Ganssle.)

Here is what the data structure that the debouncer uses to maintain state looks like. You see that I used bit fields, something that isn't obvious from the implementation.
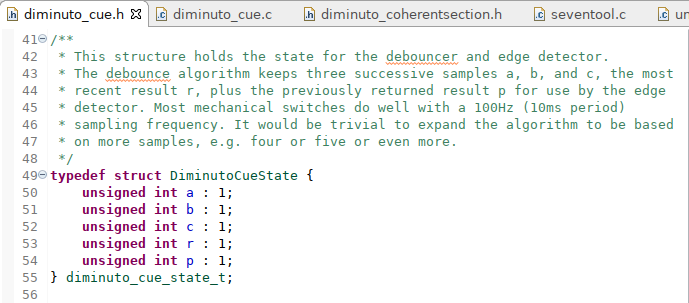
Bit fields aren't the greatest feature in C, mostly because the C standard doesn't specify in what order the bit fields occur, leaving that up to the implementation. That means you can't use bit fields portably. Big oops on the part of the C standards folks. But when I originally wrote this feature, it wasn't for Linux platforms, it was for tiny eight-bit PIC micro controllers, where data space was at a premium (fifty-six bytes of read-write memory on this particular firmware project). When I ported the code to Diminuto, I kept the bit fields.
Here is what Ghidra produces when analyzing this library compiled into a shared object file for a x86_64 target using GNU C.
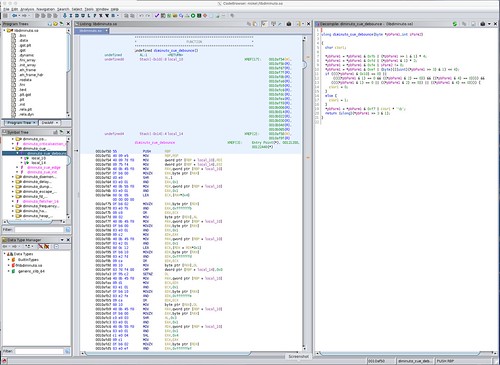
Indices into particular sections of the object module are shown on the left. The disassembly into x86_64 machine code is shown in the center (it's long, the screen doesn't contain the entire function). The decompiled C code is shown on the right.
The C code here is particularly helpful. You can see how the bit fields are handled by logical operations on the entire integer variable. (In contrast, the Harvard-architecture PIC micro controller for which this was originally written had machine instructions to do bit-wise operations which made its executable code stored on-chip in ROM much more compact.)
Many times I've had to resort to using GNU tools like objdump, or other similar target-specific tools, to disassamble files containing machine instructions - device drivers, libraries, shared objects, executables, ROM images, what have you - typically in order to debug a problem in third-party software, or to integrate some product development effort with existing legacy software, for which I didn't have access to the original source code. (Or, in a couple of darkly humorous episodes, for which my client had lost their own original source code.)
As much of a life saver as objdump is, it is limited as to what it can disassemble, and it requires that I brush up on my assembler skills, which these days are limited to writing or decoding short instruction sequences that are embedded in C or C++ code to do specialized things like implement memory barriers or generate random bits using built-in entropy generators. It would be a lot more productive to have a tool that produces (even approximate) C code.
There are commercial tools that do this. I've seen IDA Pro, a graphical Interactive DisAssembler tool produced by Belgium-based Hex-Rays, in action. The Pro version can be licensed to include a decompiler and interactive debugger for a specific architecture like x86_64 or ARM64. The licensing scheme is a little complicated, and a Pro license can run from hundreds to thousands of dollars per architecture. Many times I've longed to have IDA Pro on my laptop.
But apparently that longing never manifested into spending money on a IDA Pro license. (In hindsight, the timing for the release of Ghidra couldn't be better, since I recently revisited my budget for software reverse engineering tools.) So it was with great interest - and not a little trepidation - that I read about the NSA open sourcing their own SRE tool, and, shortly after that, installing Ghidra version 9.0 on one of my x86_64 development systems running Ubuntu 18.04. Subject to having an OpenJDK 11 available, Ghidra installed and ran without drama.
Ghidra supports a broad variety of processor architectures - many of which will cause the ears of an embedded developer to prick up - including 6502, ARM, AVR8, MIPS, PIC, PowerPC, x86, and even Z80.
But while Ghidra is a remarkable tool, it isn't perfect. A common use case in my world is that I want to reverse engineer an ARM32 or ARM64 binary using my x86_64 laptop running Ubuntu in a VM under Windows. While for the most part Ghidra is up for this - this is where its write-once-run-anywhere Java implementation really pays off - it only took me a couple of hours of playing with it to run into my first documented bug in the 9.0 version (the release dated 2019-02-28): in binary files like shared object libraries that have multiple symbol tables, it misplaces some of the symbols so that it becomes convinced that one function (identified by a symbol) is in the middle of another function (regardless of the lack of idiomatic function entry instructions).
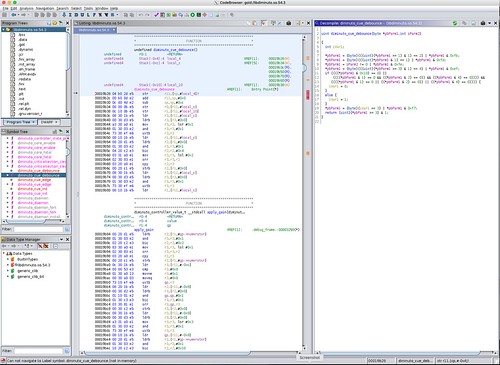
In the ARMv7 shared object binary above, Ghidra identifies the diminuto_cue_debounce function, but is convinced that the apply_gain function (which was in a completely different object module, one that implements a Proportional-Integral-Differential or PID controller, which was linked along with the debouncer and many other object modules into this common shared object) starts in the middle of it. The Ghidra bug tracker has a comment that this bug will be fixed in the next release.
Update 2019-04-02: I installed Ghidra 9.0.1 dated 2019-03-25, created a new project, reimported the pertinent file, reanalyzed it, and still see this issue when the source is compiled for the ARMv7L target (but not when compiled for the x86_64 target). What I thought was the relevant bug has been marked closed. I submitted a new bug report.
Update 2019-04-03: A Ghidra developer made the following comment on my bug report:
The import of this file looks fine. If your only concern is the 0x10000 offset when compared to objdump this is not an import error unless the file has been prelinked in which case we should use the prelinked image base. This file is a relocatable shared library which can generally be imported to any base address of your choosing (see importer options). We default to offset 0x10000 which is somewhat arbitrary. We try to avoid loading at offset 0 when possible to help avoid mistaking small constants for address offsets. The importer has an image base offset option which can be set.
I set the offset from the default of 0x10000 to 0 by selecting Import File... then Options... and editing the Image Base field. That seems to have worked. I don't know whether this is necessary for any targets other than the ARMv7L, or why it wasn't necessary for the x86_64 target which also has the Image Base set to 0x10000 by default.
Update 2019-04-04: The same Ghidra developer make the subsequent comment:
When I originally looked at your sample I had only done an import to see where the ELF loader was placing symbols. Having just run analysis I now see the issue you pointed out. You may have also noticed a bunch of DWARF related errors in your log during analysis when an image base of 0x10000 was used. Using an image base of 0 likely avoids these errors. We currently are not handling relocation records which apply to the DWARF debug data which is based at 0 for your sample. This results in DWARF analysis laying down symbols at the incorrect offset since the image base adjustment had not been applied. When DWARF data exists the 0 image base should probably be used until we are able to handle DWARF debug data relocations.
Update 2021-04-06: The latest public release of Ghidra, 9.2.2, seems to handle the multiple symbol table issue correctly (see screenshot below). As above, I set the image base to 0 here as well.
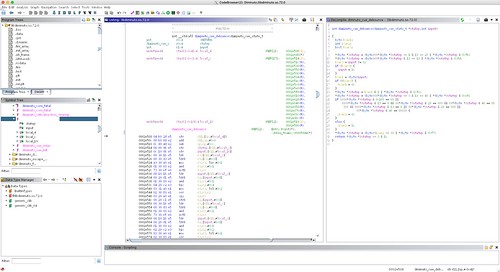
But even without doing this human labor, Ghidra produces useful artifacts for reverse engineering. Here is a screen shot of Ghidra's analysis of an ARMv7 executable binary stripped of symbols.

While Ghidra might not make it obvious, this program wipes data from a device by overwriting it with data generated from a polynomial whose initial value is seeded with a random number. It does this using synchronous I/O, bypassing the buffer cache, so that when a write operation completes, there is a chance that the data block really is overwritten, and not just scheduled to be overwritten sometime in the future. (The use case is wiping USB drives containing sensitive data in field.) Ghidra at least gives you a head start by providing a first-cut C decompile with synthesized symbol names that you can supplement with your own notes as you understand what's going on.
Important safety tip: Ghidra might make reverse engineering too easy. If you bother to read the typical End-User Licensing Agreement (EULA), you may find it specifically forbids reverse engineering the code that you just paid for. My colleagues and I have had some discussion about this when trying to integrate a recalcitrant third-party software package into our embedded product. It is not uncommon for a EULA to effectively prevent you from using the third-party product to which it applies.Ghidra is evolving into a useful tool to keep in your embedded product development kit, along with static analysis tools like nm and objdump, as well as run-time tools like valgrind, ltrace, strace, and even gdb. In future articles I'll write about using Ghidra to reverse engineer my own code that includes some of those specialized instruction sequences I mentioned earlier. And I'll keep an eye out for the next release.


No comments:
Post a Comment