When I started playing with Ghidra, the U.S. National Security Agency's recently open sourced software reverse engineering (SRE) tool, I was curious how its C decompiler dealt with instruction sequences that were perhaps outside of the normal idiomatic sequences it had been programmed to recognize. This was easy enough to find out: I had several examples of such sequences in my own repositories on GitHub.
This work was done with Ghidra 9.0 dated 2019-02-28.
(As usual, you can click on an image to be taken to a larger version.)Scattergun
Scattergun is my project to evaluate hardware entropy generators. These are devices which use transistor noise or even quantum mechanical effects to generate random bits for applications like creating unguessable encryption keys.
Two of the generators I tested in Scattergun were the Intel rdrand and rdseed machine instructions. rdrand is a general purpose hardware random number generator introduced in the Intel Ivy Bridge architecture. It generates random numbers using an algorithm that is seeded, and periodically reseeded, by a hardware entropy source built into the processor. rdseed is a hardware entropy generator introduced in the Intel Broadwell architecture. It provides access directly to the hardware entropy source built into the processor.
Scattergun provides the seventool utility that can be used to generate random bits using either rdseed or rdrand to feed to the Scattergun test suite. The functions in seventool that access those instructions look like this.
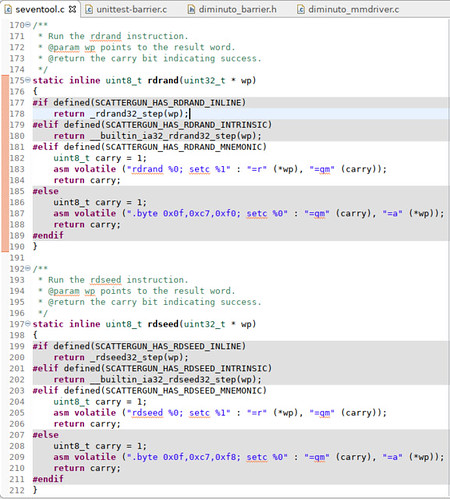
There's a lot of conditional compilation here because I needed seventool to compile run on several different vintages of GNU C compiler suites. Some of them did not have assemblers that recognized the rdrand and rdseed mnemonics. Some of them had compilers that already had built-in functions to generate the appropriate instruction sequences. But for the i7-6700T processor on which I ran these Scattergun tests, I used the compilation options that used the rdrand and rdseed assembler mnemonics. These functions (which weren't actually, as it turns out, inlined by the GNU C compiler) generate code to execute the appropriate machine instruction in-line, fetch the indication of success from the carry bit, and return that as the function value while saving the random goodness in a value-result parameter.
Here's what Ghidra had to say about these functions. In the first screen shot, I asked Ghidra to decompile the rdrand C function.
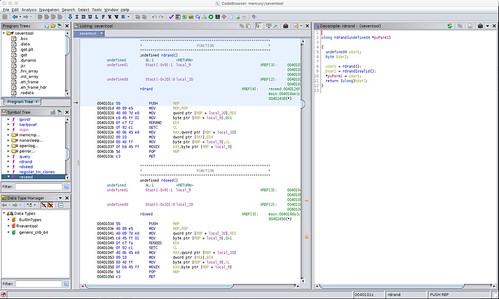
You can see the RDRAND machine instruction in the center screen showing the disassembly.
I did the same for the rdseed function.
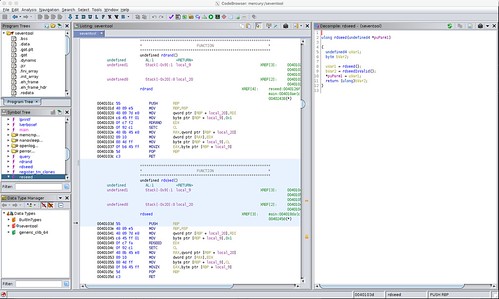
Similarly, you can see the disassembled RDSEED machine instruction in the disassembly.
Ghidra decompiled both the rdseed and rdrand instruction sequences into pseudo-function calls, both the actual machine instruction, and the check of the carry bit for success. It's pretty clear that the x86_64 instruction decode for Ghidra has been configured to recognize both of these as idiomatic machine instruction sequences. That's pretty remarkable.
Or maybe not. I probably shouldn't be surprised that the premiere encryption cracking organization on the planet is especially interested in detecting applications that use hardware features especially designed for creating encryption keys. (The fact that I was able to get to this point within about an hour of installing Ghidra might say something about the hazards of meta-analysis revealed by open sourcing tools like this.)
Diminuto
Diminuto, my C systems programming library for (mostly) Linux/GNU platforms, includes some definitions to make it easy for me to play with memory barriers: machine instruction sequences available on many architectures (not just x86_64) that enforce cache coherency on multi-core processors. The good news is that multi-core architectures have machine instructions to explicitly do this (that is, they do if they work), or at least instructions that do this as a side effect. The better news is that modern GNU C compilers have built-in pseudo-functions that generate the appropriate instruction sequences for each different architectures, making it easier to write portable code that use memory barriers.
(I confess there is a lot of "do as I say and not as I do" in the Diminuto memory barrier code, which is pretty experimental. You are for the most part much better off coding POSIX mutex operations, which use memory barriers as part of their implementation. Diminuto can help you with that, too.)Here is a unit test program in Diminuto that calls the general memory barrier function diminuto_barrier several times. It then calls the read barrier function diminuto_acquire, and then the write barrier function diminuto_release. Interspersed are assignment operations to a volatile variable that in my naivety I had hoped would keep the compiler from optimizing them out.
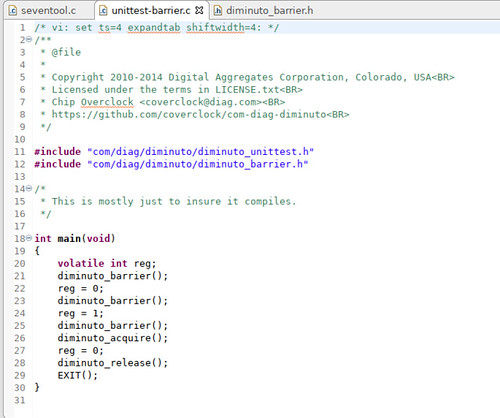
A read barrier (which is said to have acquire semantics) is intended to block the execution core until its cache has been updated with the latest values from other cores. A write barrier (with release semantics) is intended to block the execution core until its cache changes have been propagated to the other cores. The general barrier does both.
Here is the implementation of all three functions.
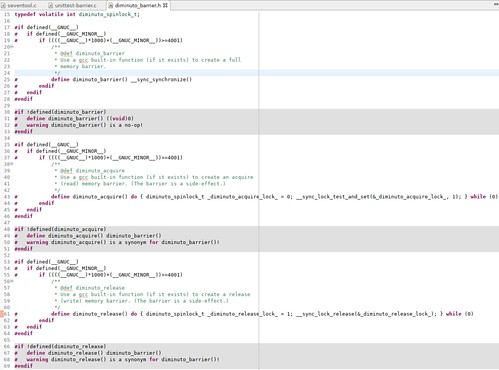
You can see that they are all implemented as preprocessor definitions that expand to predefined GNU C functions. The __sync_synchronize function implements a general (both read and write) memory barrier. The read and write barriers are a little more complicated; they use the GNU C __sync_lock_test_and_set and __sync_lock_release functions, not for their intended purpose as machine-level synchronization mechanisms using busy waiting (spin locks), but because they implement read and write memory barriers as a side effect.
Here is how Ghidra decodes this unit test for code compiled for the x86_64.
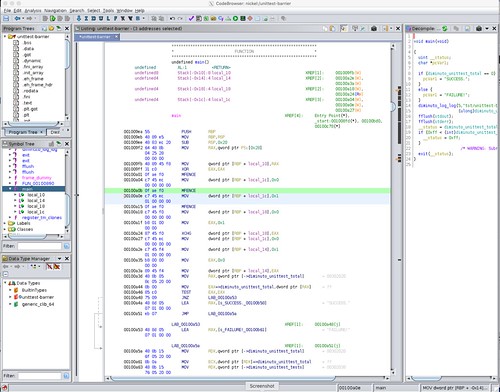
The disassembly in the center screen is straightforward. There are the three MFENCE instructions corresponding to the diminuto_barrier function calls that each expanded into __sync_synchronize. You can see the MOV instructions that does the variable assignment. You can see the XCHG that implements the __sync_lock_test_and_set in diminuto_acquire (there's no loop because we just want the read barrier as a side effect), and a MOV that implements the __sync_lock_release in diminuto_release.
The C decompile on the right is more problematic. Not only are none of the memory barrier operations represented in any way, but the assignment statements that were in the original C source are missing as well. In fact, the only code shown in the decompile is that which was generated in the unit test framework EXIT macro that handles the end of test processing. The entire body of the unit test is gone.
It is no more than a guess on my part, but maybe Ghidra fell into a machine instruction sequence that it didn't recognize, and rather than add a notation in the decompile it simply ignored it. The authors of Ghidra have a lot more experience using it to reverse engineer software using Ghidra than I do (which is, basically, none). But this seems unfortunate, since the use of memory barriers is a common idiom in the kinds of low level work that I do, particularly with devices that expose data registers by memory mapping them into the processor address space.
Hazer
Hazer is my project to evaluate Global Navigation Satellite System (GNSS) receivers, of which the Global Position System (GPS) receiver that may be in your mobile phone is one example. The gpstool utility in Hazer makes use of Diminuto scoped operators: operators that have an explicit begin (opening) and end (closing) syntax that correspond to underlying begin and end semantics.
One example makes use of the memory barriers we just discussed to implement the Coherent Section scoped operators.
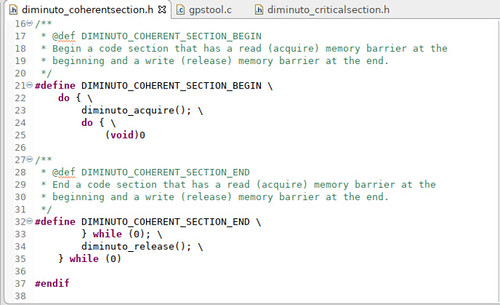
These Coherent Section operators, when used at the beginning and ending of a section of code, automatically perform a read barrier at the beginning of the section and a write barrier at the end of the section.
Perhaps a little more typical are the Critical Section scoped operators.
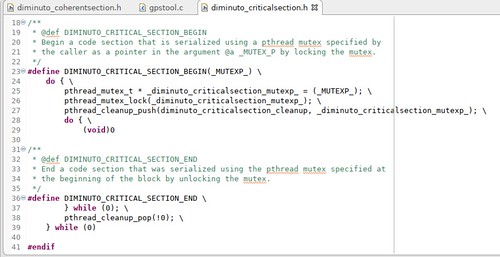
The Critical Section begin operator automatically causes the application to acquire (block until it is available and then lock) a POSIX mutex passed in by the application, and the end operator automatically releases (unlocks) the mutex as the flow of control leaves.
The Hazer gpstool utility has an option to monitor the 1PPS (One Pulse Per Second) 1Hz timing signal that is generated by some GNSS receivers. One of the ways that serial-attached receivers generate this pulse is by toggling the Data Carrier Detect (DCD) control line on the serial port. gpstool uses a separate thread to follow DCD and communicate its state back to the main thread.

The dcdpoller function uses the Coherent Section scoped operators to bracket the reading of the done variable that tells the thread to exit (when, for example, the application terminates), and the more conventional Critical Section scoped operators to synchronize read-modify-write access to the oneppsp variable that it uses to inform the main thread that a 1PPS event has occurred. (The function can also optionally strobe an external GPIO pin to pass the DCD state on to another device.)
I routinely run gpstool on both x86_64 and ARM architectures. Here is the Ghidra analysis of the dcdpoller function on the x86_64.
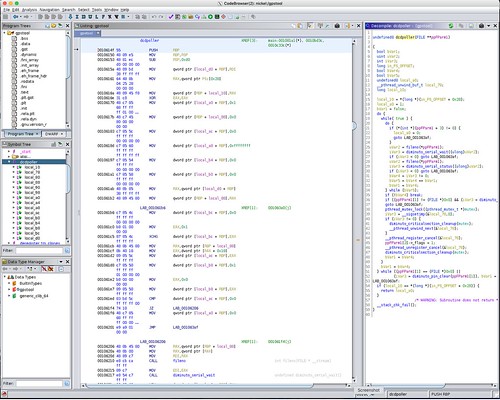
The XCHG and MOV instructions that form the beginning and ending of the Coherent Section are clearly visible in the disassembly, but are completely absent in any form in the decompile. But at least the check of the done variable is present in the decompilation. The beginning and ending of the Critical Section, including the handling of the POSIX mutex clean up, is well represented.
Here is the Ghidra analysis of the same function compiled for the ARM.
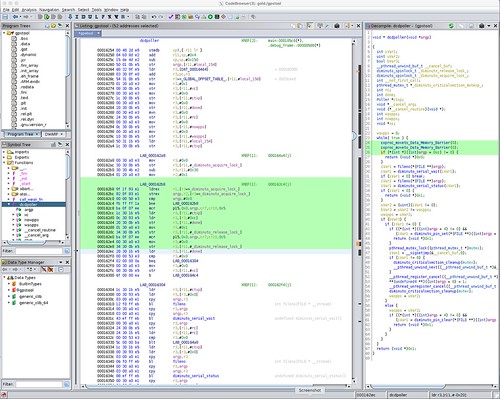
The ARM ldrex (Load Exclusive) and strex (Store Exclusive) instructions are how the ARM implements an atomic test-and-set operation. These are visible in the disassembly where the original C code enters the Coherent Section. The lock is released when the flow of control exits the Coherent Section via (I think) conventional mov (Move) and str (Store) instructions. The decompile represents this using two successive coproc_moveto_Data_Memory_Barrier pseudo function calls. The disassembly shows that the done value is accessed inside the Coherent Section, but this isn't at all obvious from the decompile. The decompile of the Critical Section using the POSIX mutex was recognizable as being the same operation as in the x86_64 analysis, which is no surprise; it's probably the same underlying implementation, with only minor differences for architecture specific operations like spin locks.
(It occurred to me later to do a Ghidra analysis of the Diminuto memory barrier unit test compiled for the ARM instead of the x86_64. I got results consist with this Hazer analysis: the presence of many coproc_moveto_Data_Memory_Barrier pseudo function calls in the decompile, but the body of the unit test was missing except for an empty do-while-false block.)
Update (2021-04-06): The latest Ghidra public release, 9.2.2, appears to address the issue of the missing body of the unit test in the code compiled for an ARM7 (see screenshot below).

I'm not an expert in either x86_64 or ARM assembler coding, but at least I was able to make my way through the disassembled listings without much drama, and with only one reference to a processor manual. The decompiled listings were useful as well, but it would have been easy to have been mislead had I not been the author of the original program being analyzed and so knew what to expect.
Ghidra is going to be my go-to tool for this kind of analysis. In fact, I can easily see using it as a static analysis tool when coding specialized instruction sequences in C or C++ to make sure I haven't botched something. I have already decided to make some changes to the few (okay, two) places in my libraries where I make use - probably inadvisedly - of Coherent Sections outside of unit tests. I probably wouldn't have figured that out without Ghidra.
Ghidra ain't perfect, but it ain't bad - I'm amazed the decompiler works at all - and the price is right.


No comments:
Post a Comment