So when I decided it was time to learn about version 6 of the Internet Protocol (IPv6), I knew I was going to have to spend some time writing some code. Since I make my living as a product developer, with a profitable emphasis on the low level, I was interested in how applications and systems would be affected by the API changes brought on by IPv6 when compared to that of the venerable version 4 Internet Protocol that I - and everyone else - had been using for decades.
Internet Protocol version 4 (IPv4) is the historical foundation for most of the Internet and World Wide Web that we all know today. But for reasons that will become clear if you make it through this lengthy article, IPv6 is becoming increasingly necessary in today's world of global deployments, mobile devices, and the Internet of Things (IoT).
(Update 2019-11-26: I gave a talk on this topic to one of my clients, who was kind enough to record it and make it available online: "Roundhouse" . You can find a PDF of the slides for this talk on the web as well: Roundhouse.pdf .)
(You can click on any of the images in this article to be taken to a larger version.)The Big Picture
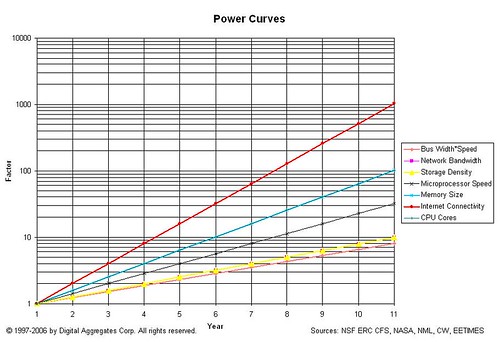
Long time readers will recognize this logarithmic graph: it compares the relative exponential growth rates of several technological domains: microprocessor speed, number of CPU cores, memory size, etc. It's easy to see that the rate of growth of Internet connectivity outstrips all of the other domains, even though those other domains are enablers of that growth. But technologists architect, design, implement, and pay for systems that meet anticipated needs over a relatively short time window. Designing for the far future is hard to justify economically, especially when such designs may not work for the circumstances you find yourself in today.
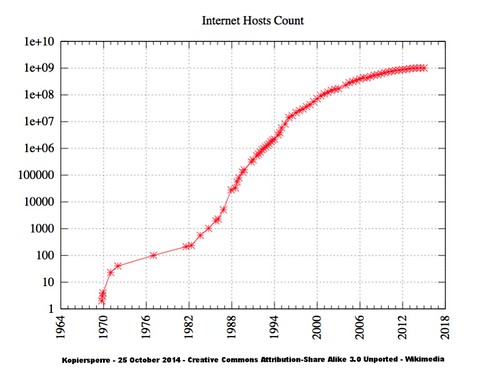
This second logarithmic graph shows the growth in Internet connectivity by year. The years are important here: IPv4 was architected, designed, and deployed roughly from 1974 to 1983 when it was established as the standard protocol for ARPANET, the U.S. defense department network that was what passed for the Internet in those days. ARPANET was a child of the Cold War: both its funding and its design revolved around this fact.
When IPv4 became the standard, there were hundreds of hosts on the Internet. One of the problems with living on an exponential growth curve, particularly at the beginning, is that it may be difficult to see that you're living on an exponential growth curve. And even if you do, it may be difficult to convince other people that you have to plan for billions of hosts on the Internet.
A History Lesson
When people say "IP", at least in the United States, typically IPv4 is the protocol they mean. It is the protocol most folks in the U.S. use today, whether they know it or not, when they cruise the web. It is the protocol implemented by the WiFi router they bought at their local electronic store. When folks say "TCP/IP", it is somewhat of a misnomer: Transmission Control Protocol (TCP) is one of several protocol layers that runs on top of IPv4. User Datagram Protocol (UDP) is another that is also widely used by Internet-enabled applications.
IPv4 was planned around what its designers could foresee. It used 32-bit addresses, really just integer numbers, allowing for an almost inconceivable at the time 4.2 x 109 or more than four billion hosts. The addresses are by convention written as four octets (8-bit numbers), in decimal, separated by periods.
100.125.125.255
When the Domain Name System (DNS), a distributed database system that maps domain names like chipoverclock.com to one or more IPv4 addresses, came along, those addresses were stored in records referred to as type A. A for Address. (This will become important later.)
Since each network on the Internet needed a unique block of address, and each host a unique address within that block, there eventually was a U.S.-based authority that as responsible for assigning and keeping track of blocks of addresses, the Internet Assigned Number Authority (IANA). Organizations that connected their network to the Internet were assigned small or large blocks of addresses by the IANA, depending on their anticipated need.
These blocks were organized using a scheme that made it easy to tell what part of the address was the network part and what was the host part; different ranges of address blocks were in different classes. There were just three classes, A, B, or C, depending on how the network and host values in the address were divvied up: for addresses in the class A range, only the first octet or byte identified the network; class B, the first two octets; class C, the first three octets. So each class had a different ratio of the number of networks to the number of hosts on a particular network that could be represented.
As the Internet grew from hundreds to millions (and later, billions) of computers, and its geographic span grew as well, the Internet evolved from a U.S. defense internetwork designed to survive a nuclear strike into a global internetwork that included networks and computers that were part of commercial, educational, cultural, government, and other kinds of organizations. The class scheme that mapped addresses into networks and hosts turned out to be too inflexible for the growth it was being asked to address. And organizations outside of the United States rightfully objected to a U.S.-centric organization controlling the allocation of what had become a valuable and limited global resource. (The IANA probably didn't really want the job of managing IPv4 addresses for everyone in the world, either.)
In 1993, the class scheme was replaced with a new scheme called Classless Inter-Domain Routing (CIDR). With CIDR, the division between the network and host portions of the address could occur on any bit boundary, and could be different for every network. You could no longer tell just by looking at an IPv4 address what part identified the network and what part identified the host. (Subnet masks made even more complex schemes possible, but you had to be a masochist to use them.) This made routing much more complicated and computationally expensive. But it gave Internet architects a lot more flexibility in assigning and managing blocks of addresses.
CIDR was made possible by those very same exponential curves that caused the problem in the first place. While the WiFi router that sits in my family room is a relatively modest piece of kit, so-called core routers that handle traffic on the Internet backbone are effectively special purpose supercomputers, and are priced accordingly. The growth of the Internet and the growing computational cost of routing strains our ability to build, or pay for, routers to handle IPv4 traffic.
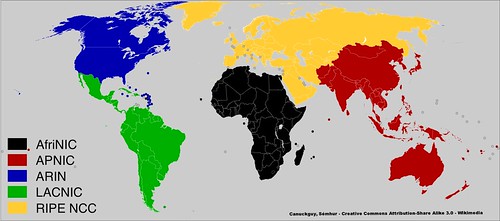
The globalization issues was addressed by establishing five broad regional organizations to control the allocation of IPv4 addresses: Africa (AfriNIC), Asia-Pacific (APNIC), North America (ARIN), Latin America and Caribbean (LACNIC), and Europe (RIPE NCC). The IANA still existed, but it now handed out large blocks of addresses to these regional organizations, who were then responsible for divvying up those blocks to organizations in their region of responsibility.
The Limits to Growth
So that's pretty much were we are now. How are we doing with the whole IPv4 address thing? It is probably no surprise that folks in the know watch this closely. And it's not hard to find web sites that give you up to the minute real-time statistics on how many IPv4 addresses are left. Here's a snapshot I took a month or so ago from a web site managed by Hurricane Electric, an Internet service provider.
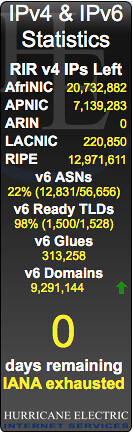
Huh. That's not good.
According to this, the IANA has no more IPv4 address blocks to give out. And the well at the American Registry of Internet Numbers (ARIN) is dry too.
Yep, this isn't a joke. North America is clean outta IPv4 addresses. There are no more to be had. And at the rate the Internet is growing, the other regions won't last much longer either.
So how is it that every new mobile phone and tablet has an Internet connection? And as soon as someone moves out of their parents' house, their first purchase is a WiFi router so they have Internet connectivity in their dorm room, apartment, condo, or house?
There are basically two ways this is being handled.
- If an organization in North America requests a block of IPv4 addresses, they go on a waiting list. As organizations give up IPv4 address blocks (a rare occurrence but it does happen), the addresses are aggressively recycled and assigned to folks on the waiting list.
- Rampant cheating.
If those apps are using TCP or UDP, this is done using a port number. Port numbers are 16-bit numbers known only to TCP or UDP; IP really has no idea they even exist. Sixteen bits gives us about 6.5 x 104 or sixty-five thousand possible values. Port numbers are conventionally written as a single decimal number. For example, the standard port number for a web server is port 80. When you cruise the web and clink on a link, you are sending data to port 80 to the web server on whatever web site you are visiting.
As we will see later in this article, much of my testing was done using port 5555 to identify a particular process listening for incoming connections on a particular server. There's nothing special about 5555; I chose it because it wasn't already being used and it was easy for my tired old brain to remember.
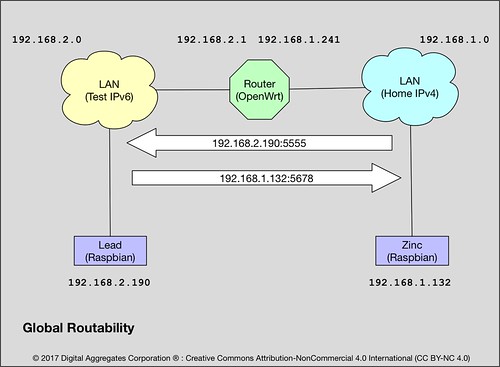
If you and your buddy were to peer into the web pages that manages each of your WiFi routers in your respective homes, or the apps that manage your internet connectivity of your mobile phones, tablets, or laptops, you might be surprised to find out that your router is assigning the same IPv4 addresses to the Internet connected devices on your WiFi network as your buddy's. My iPhone has the address 192.168.1.145 on my home network. Yours might too. And my WiFi router has the address 192.168.1.1. It is extremely likely yours does as well.
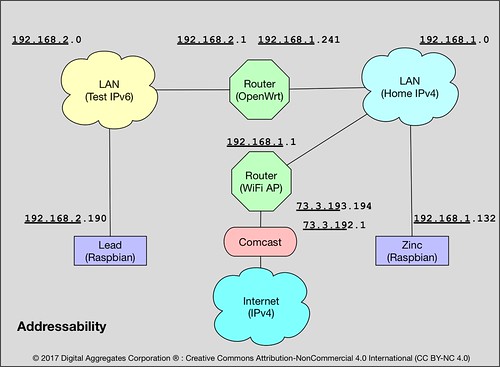
In order to spread the use of IP addresses further, when it became clear that we were heading for Peak IPv4, Internet architects came up with some clever strategies of exploiting that largely unused port number range. Largely unused because at the time no one could conceive of a single computer really being able to use sixty-five thousand connections. Through mechanisms called Network Address Translation (NAT) and Port Forwarding (I've never seen an acronym for that but let's call it PF), your home router (probably) has an actual unique IPv4 address assigned to it by your Internet Service Provider (ISP), but every IPv4 address that is used behind it has a private address, which is to say, it is not unique, and no one outside of your home network ever sees it.
Instead, as far as the outside world is concerned, all of your Internet connections appear to terminate at your router, to its unique IPv4 address, each connection with its own unique port number. Your router maps every single packet over each of those connections to some private address (via NAT) and port number (via PF) on your home network. The devices on your home network, with their private IPv4 addresses, are not globally routable. Which is to say, they are effectively not on the Internet. Only your router is on the Internet. Maybe. Probably.
There are a few implications of this.
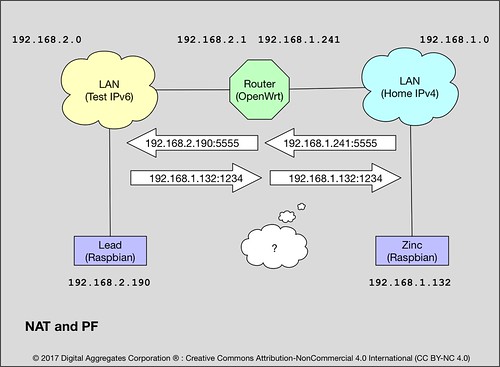
- NAT and PF are expensive. Your router has to break apart every IPv4 packet and deal with the TCP and UDP layers, rewriting data in every single packet to preserve the illusion of Internet connectivity. This makes the "NATting" router an intimate party participating in the end-to-end connection, not a simple "bucket brigade" just shipping packets between network interfaces. As the private network behind a router grows, this becomes less and less feasible.
- This packet rewriting has to be done in both directions, since the return address of any reply packets have to be modified to point to the router, not to the endpoint that actually sent the reply packet.
- Some types of connections using a connection oriented protocol like TCP have state that the NATing router must maintain. So the router has to crack open the higher layer protocol portion of the packet and identify whether the TCP message is, for example, starting or ending a connection, so that the router can create or destroy any state it must maintain about the connection.
- It is likely that NAT and PF are being done at both ends of the connection, which is to say, both the client and the server are behind NATting routers. So the overhead of NAT and PF is endured twice.
- The IPv4 address shortage is so severe, that the address assigned your router by your internet service provider (ISP) may itself be a private address. If so, then there is another entire layer of NAT and PF going on of which you are not even aware. Worse, the sixty-five thousand port number limit occurs at which ever router up the line that actually has a globally routable IPv4 address. And the computational load on that router is proportionally greater.
- Those exponential growth curves make it more and more likely that a single computer, or network of computers, or internetworks of computers, behind a single router, can actually support sixty-five thousand or more simultaneous data streams. So it becomes increasingly possible for Internet connections to fail because all the port numbers are in use.
- It has been clear for a long time that the solutions used to extend the usefulness of IPv4, like NAT and PF, were limited not just in scalability, but in functionality. The need for a centrally implemented and managed point of connectivity on which to perform NAT and PF had major implications for the mobile devices that had to switch not just from cell tower to cell tower, but from provider to provider, as the devices change location. And the lack of global routability didn't fit with many of the expected network architectures of the Internet of Things in which small devices might be independent of central management.
This is kind of a big deal.
So from about 1995 to 2005, Internet engineers designed and implemented Internet Protocol version 6 to solve as many of these problems as they could foresee. They could have doubled the address space of IPv4 just by adding a single bit. Or increased it by a factor of four billion by doubling its size to sixty-four bits. But instead, they cranked IPv6 addresses up to 128-bits in length. This yields about 3.4 x 1038 possible values, a number so big we don't have a word for it, although hundred billion billion billion billion might serve. This vast address range means really large blocks of addresses can be reserved for special purposes, and addressing can be designed to reduce the computational load on routers by eliminating complexities like CIDR.
IPv6 addresses are conventionally written as eight hextets (16-bit numbers) in hexadecimal, separated by colons.
2600:100e:b003:f288:c265:6cae:85c8:4f68There are no classes. IPv6 separates the fields in an address in a CIDR-like fashion, on bit boundaries. There is some advantage to separating the fields on a hextet, octet, or hex digit boundary when possible, just for readability. As we will see in some examples below, the first hextet of the address carries special meaning, indicating whether the address is private or global or what not.
Typically, IPv6 addresses are divided up into a 48-bit prefix that identifies the organization (2600:100e:b003), 16-bits that identifies the network within the organization (f288), and a full 64-bits to identify the interface (c265:6cae:85c8:4f68). The separation between the network and host portions of the address is specified CIDR-like, for example /64 above. Some ISPs provide a 64-bit prefix (/64) instead of a 48-bit prefix (/48), but that merely means they aren't allowing you to further divvy up your address space into subnetworks. Other prefix lengths between /48 and /64 are possible, with /60 being a common one. A /128 prefix really means your ISP is assigning you a single IPv6 address.
Why interface, and not host? Because when IPv4 was invented, no one could conceive of a computer, except for routers, having or needing more than one network interface. But today, your mobile phone has a network interface to the cellular network, and another to the WiFi network. Your laptop may have three network interfaces it uses simultaneously: a cellular modem, a WiFi radio, and a wired Ethernet connection. The interface portion of the IPv6 network is sixty-four bits to make it trivial to map commonly used lower level hardware addresses (like a 48-bit Ethernet address) easily into the interface portion of an IPv6 address.
If you access a domain name that can map to an IPv6 address, like google.com can, that address is stored in a type AAAA record in DNS. Type AAAA because an IPv6 address record is four times bigger than an IPv4 address record. No, really.
TCP and UDP still exist, and for the most part run as they did before but now on top of IPv6. (There are a few differences in how checksums are calculated by these protocols, but that's immaterial to this discussion.)
IPv6 is the new world order.
Except IPv6 is not new. As early as 2004, the Linux 2.2 kernel saw an IPv6 protocol stack implemented alongside its existing IPv4 stack. By 2005, IPv6 saw broad deployment among many internet service providers. IPv6 is being widely used in parts of the world - particularly Asia and Europe - that see high growth in Internet connectivity, high population density, and nearly ubiquitous use of mobile devices. Mobile network providers in particular are driven to use IPv6 both for its scalability and the global routability it provides to the devices that use it.
But in the United States, IPv4 is a victim of its own success, so broadly deployed and used that a sudden wholesale conversion to IPv6 is just not practical. Never the less, numbers don't lie: the move to IPv6 is necessary and inevitable, driven by the continued exponential growth of Internet connectivity.
Fortunately, you can easily experiment with IPv6, even in your existing IPv4 infrastructure.
The IPv6 Man Cave

This is what passes for my lab bench in my home office. Somewhat remarkably, there are at least eleven Linux-based systems pictured here, including an Android phone, an Asterisk PBX, and my Linux/GNU server named "Mercury" that I use for software development. To the lower right you can see an anti-static mat with a pile of stuff on it. This is my IPv6 testbed.

"Roundhouse" is my tiny IPv6 router. It is a Raspberry Pi 2 in a black case on the right that runs OpenWrt, an open source router package. Roundhouse has two Ethernet connections, one to my IPv4-based home network (an Ethernet switch to the far right), and one to my IPv6 testbed network (the Ethernet switch near the center).
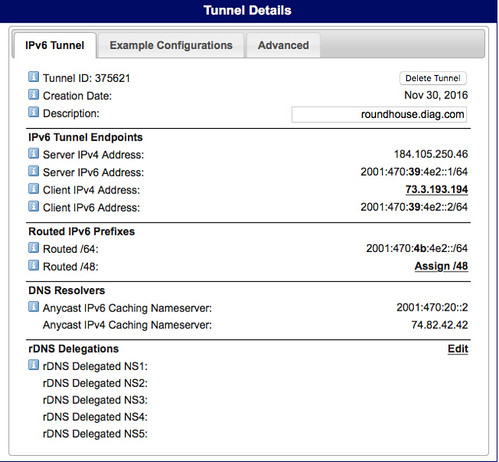
OpenWrt supports a 6in4 tunneling mechanism that allows you to reach the IPv6-based Internet by passing IPv6 packets over an IPv4 connection to an internet service provider that acts as a tunnel broker. Hurricane Electric provides just such a capability. My IPv4 ISP is Comcast, but my IPv6 ISP is Hurricane Electric; I tunnel through the former to reach the latter.
Important Safety Tip: when you implement such a tunnel, you are driving a big hole right through the firewall in your IPv4-based router. Furthermore, since IPv6 eliminates the need for NAT and PF, it also eliminates the additional security that those mechanisms provide to hide your home network from the Internet. IPv6 potentially makes all devices connected to it globally routable, that is, reachable from anywhere else on the IPv6-based Internet. Getting your firewall right will be even more crucial when you use IPv6. I'm paranoid enough that the IPv6 network I've documented here no longer exists. Before I deleted that Hurricane Electric tunnel, I did a lot of IPv6 firewall testing using network penetration tools like nmap. So should you.
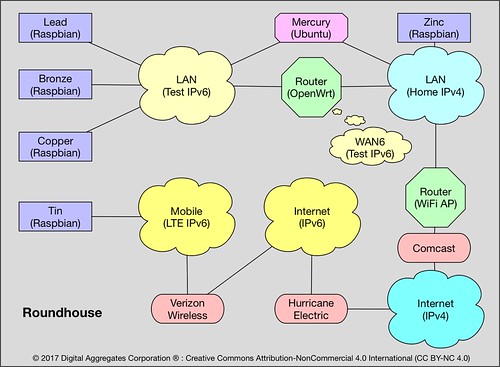
"Tin" is a Raspberry PI 3 whose sole network connection is via a cellular modem to Verizon Wireless' LTE network that supports both IPv4 and IPv6.
"Lead" and "Copper" are Raspberry Pi 3s, and "Bronze" a Raspberry Pi 2, that are all connected to the IPv6-based test network.
"Zinc" is a Raspberry Pi 3 that is connected only to the IPv4-based home network.
Mercury, my development server, has two Ethernet interfaces, and is connected to both the IPv4 home network and the IPv6 test network.
All of the systems in the testbed run some version of Linux, and all have dual protocol stacks: they can speak both IPv6 and IPv4 on the same network. Any organizational transition from IPv4 to IPv6 is likely to be gradual, and running dual stacks is in my opinion the only reasonable approach. (I've also routinely connected Mac and Windows systems to this network, just plugging them into the testbed Ethernet switch, and they worked just fine using IPv6 too.)
Let's suppose you wanted to run a server application on Lead, one of the Raspberry Pi 3s on the IPv6 test network. What IP address, v4 or v6, might you use to reach it? It turns out there are a lot of choices, and they all work.
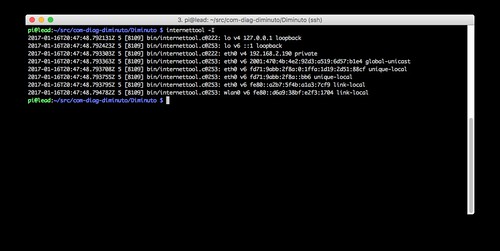
192.168.2.190 is Lead's private IPv4 address assigned by good old DHCP on the router. This works because Lead runs both the IPv4 and IPv6 protocol stacks and can use them interchangeably on the test network.
0:0:0:0:ffff:192.168.2.190 is a v4-mapped IPv6 address: an IPv6 address with an IPv4 address encapsulated in it. This is the standard approach of presenting an IPv4 address to the IPv6 protocol stack. It can be abbreviated ::ffff:192.168.2.190, the IPv6 convention being :: means "insert as many zeros here as you need".
192.168.1.241:5555 is the static IPv4 address of the Roundhouse router on the home network, plus the port number 5555 that I defined. This works because I added an old-school NAT and PF rule to the Roundhouse firewall to map all IPv4 packets arriving on port 5555 on the router to the same port number on Lead. The router has to handle the mapping and rewriting of every single packet that arrives on this port. This is likely how your own IPv4 network works today.
fd71:9abb:2f8a::1ffa:1d19:2d51:88cf is a unique-local or private IPv6 address created by Lead using the fd71:9abb:2f8a prefix provided by the router, a 0 subnet, and a 1ffa:1d19:2d51:88cf interface address created using a cryptographic hash. Yes, IPv6 has the equivalent of IPv4 private addresses, and like IPv4, they are not globally routable.
fd71:9abb:2f8a::bb6 is another unique-local IPv6 address assigned by the router using DHCPv6. It has the same prefix and subnet number as the prior unique-local address, and an interface address generated by DHCPv6.
fe80::a2b7:5f4b:a1a3:7cf9 is a link-local IPv6 address, another form of private address. It is created by Lead just to talk to its router, and is only visible on the link that they share (in this case, the Ethernet).
fe80:d6a9::38bf:e273:1704 is another link-local IPv6 address, this one assigned to the Raspberry Pis wireless interface which I didn't use in this project.
::1 is the IPv6 equivalent of the IPv4 loopback address 127.0.0.1. Lead could use either of these addresses to talk to itself.
2001:470:4b:4e2:92d3:a519:6d57:b1e4 is finally what you were waiting for. It is the global-unicast IPv6 address, with the globally routable prefix 2001:470:4b assigned by Hurricane Electric, the subnet 4e2 also assigned by Hurricane Electric (because I elected not to subnet my tunnel), and the 92d3:a519:6d57:b1e4 interface address generated using a cryptographic hash (some IPv6 stacks use a form of the Ethernet MAC address here, but by default this stack uses what is essentially a random number).
Those Who Can Do
So let's run a server on Lead, and a client that talks to it on each of the other systems in the testbed. We'll use a program called internettool that is part of my Diminuto C-based package of Linux/GNU systems programming tools.
Diminuto is open source (LGPL), and portions of it have found their way in to a number of products shipped by several of my clients. So don't be too surprised if it turns up in your travels. Besides tools to test network connectivity, Diminuto also has tools to test other stuff, like General Purpose Input/Output (GPIO) hardware and serial ports, interfaces that are commonly used in my line of work.In each of the screen shots below, all of which are from the same test session, I let the test run for an hour or two, then suspended each of the programs so that the command that I used for the test is displayed by the shell.
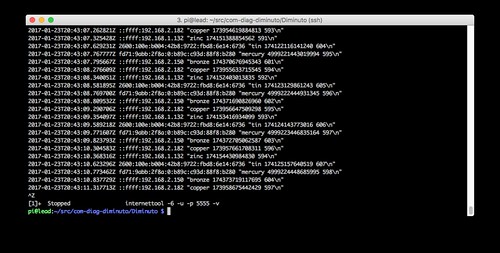
Lead is running internettool in server mode: it receives packets and sends them right back to the sender. It is using IPv6 (-6) and UDP (-u). It is listening on port 5555 (-p 5555). Each time it receives a packet, it displays it proceeded by a timestamp and the IPv6 address from which it was received.
Perusing the source IPv6 addresses reported by Lead yields some interesting stuff.
Zinc packets are arriving from the v4-mapped IPv6 address
::ffff:192.168.1.132on the IPv4 home network (the network part of the IPv4 home network is 192.168.1).
Tin packets are arriving from the global-unicast IPv6 address
2600:100e:b004:42b8:9722:fbd8:6e14:6736which is the IPv6 address Verizon Wireless assigned to the LTE modem for this test.
Mercury packets are arriving from the unique-local IPv6 address
fd71:9abb:2f8a:0:b89c:c93d:88f8:b280private to the IPv6 test network.
Bronze packets are arriving from the v4-mapped IPv6 address
::ffff:192.168.2.150on the IPv6 test network (when using IPv4, the network part of the IPv6 test network is 192.168.2).
Copper packets are arriving from a v4-mapped IPv6 address
::ffff:192.168.2.182on the IPv6 test network.
So what do the clients look like?
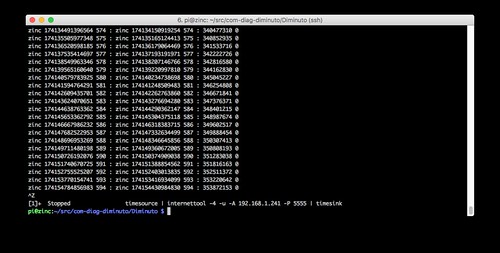
Zinc is running internettool in client mode: it sends packets and expects to receive the same packet back. It is using IPv4 (-4) and UDP (-u) - recall that Zinc is on the IPv4 home network. It is sending to the static IPv4 address of the router (-A 192.168.1.241) using port 5555 (-P 5555) - it is relying on the old school NAT and PF mechanism provided by the OpenWrt router, which must crack open and rewrite all of Zinc's data packets.
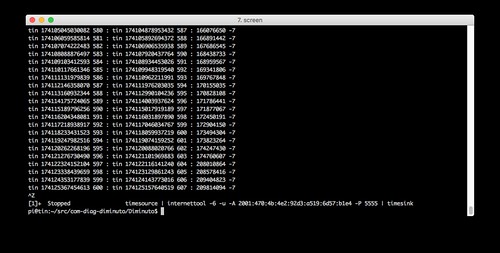
Tin is running internettool in client mode. It is using IPv6 and UDP. It is sending to the global-unicast IPv6 address of Lead (-A 2001:470:4b:4e2:92d3:a519:6d57:b1e4) - recall that Tin is on the Verizon LTE network - using port 5555. Note the -7 reported by Tin: this indicates that it has lost seven packets, which is more than ten percent (the sequence number of the last received packet is seven behind that of the last sent packet). This is possible when using UDP, and seems to be typical of the LTE cellular network. None of the other clients in the text fixture lost any packets.
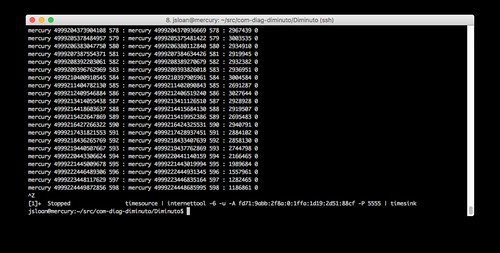
Mercury is running internettool in client mode. It is using IPv6 and UDP. It is sending to the unique-local IPv6 address of Lead (-A fd71:9abb:2f8a:0:1ffa:1d19:2d51:88cf) - it can do this because they are on the same local area network - using port 5555.
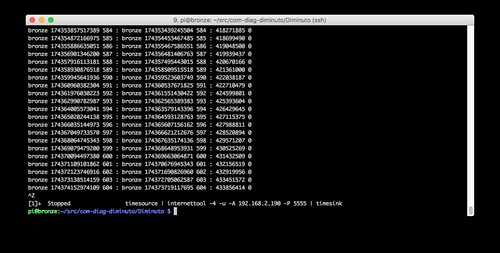
Bronze is running internettool in client mode. It is using IPv4 and UDP. It is sending to the IPv4 address of Lead on the IPv6 network (-A 192.168.2.190) - it can send directly, not using NAT and PF - using port 5555.
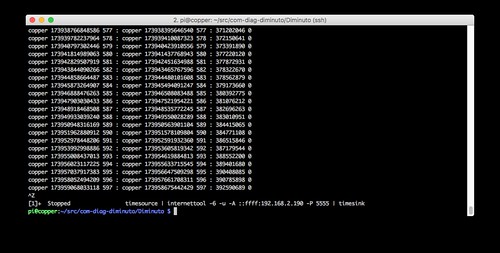
Copper is running internettool in client mode. It is using IPv6 and UDP. It is sending to the IPv4 address of Lead on the IPv6 network but in a v4-mapped IPv6 address (-A ::ffff:192.168.2.190) using port 5555.
All of these clients, using a broad mixture of addressing modes, and using either IPv4 or IPv6, were able to concurrently communicate bidirectionally with the same server on Lead, with the server using a single listening socket attached to port 5555 and IPv6.
Practical Considerations
Most of the commands you use for IPv4 either work with IPv6 or have IPv6 counterparts or equivalents. You use the IPv6 version of the command if you are specifying an IPv6 address, or if you want make sure the command uses the IPv6 address corresponding to the domain name you use (because most hosts that have an IPv6 address also have an IPv4 address, and DNS can map the domain name to either of them). Here are examples of how some commands change for IPv6.
ping6 (instead of ping)
traceroute6 (instead of traceroute)
ssh -6
ip -6
ip -6 neigh show (instead of arp)
wget -6
route -A inet6
nslookup -query=AAAA
host -t AAAA
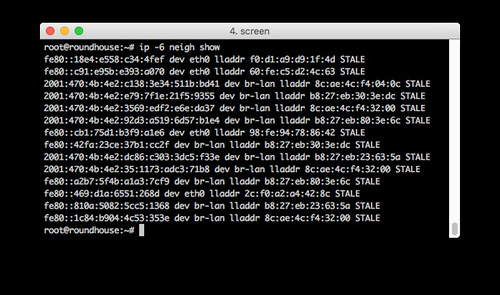
This is an example of using ip -6 neigh show on the router. Notice how both link-local (fe80:) and global-unicast (2001:) addresses are shown. You have to correlate them using the Ethernet link-level addresses (e.g. lladdr f0:d1:a9:d9:1f:4d) to know which IPv6 addresses point to the same physical Ethernet interfaces.
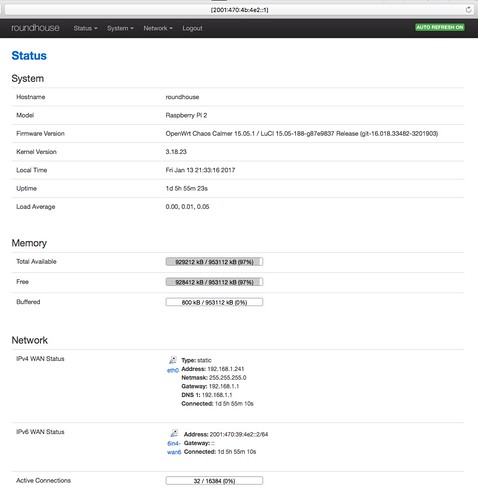
If you want to specify an IPv6 address in a web browser, the standard is to put the IPv6 address in square brackets. This is a web page of the management interface (called LuCI) of the OpenWrt router. You can see the URL with its IPv6 address in square brackets
[2001:470:4b:de2::1]in the address bar at the top.
You can see that the router reports its IPv4 address on the home network (which is its WAN connection to the IPv4 Internet) and its IPv6 address of its end of the Hurricane Electric tunnel (which is its WAN connection to the IPv6 Internet).
Also note that the IPv4 WAN has as its default gateway my home WiFi router with its typical private address 192.168.1.1, but for the IPv6 WAN there is no default gateway. While OpenWrt allows you to specify a default gateway, it may not be necessary; IPv6 has mechanisms for a router to advertise itself on a LAN as the default gateway so that hosts can self-configure their route to the outside world.
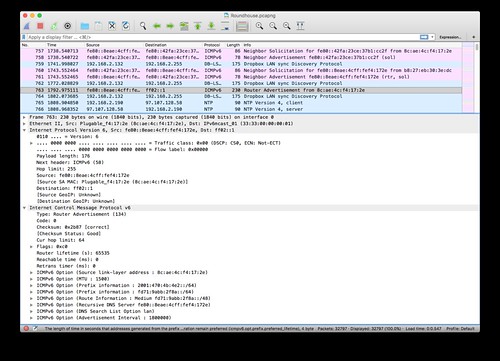
Wireshark works just fine with IPv6. In this example you can see that it displays both IPv6 and IPv4 packets on the same LAN. I've selected to decode a router advertisement packet in which the OpenWrt router provides its Ethernet link-layer address, both the Hurricane Electric globally routable IPv6 prefix and its IPv6 unique-local prefix, an IPv6 routing prefix, and the link-local IPv6 address of a DNS server.
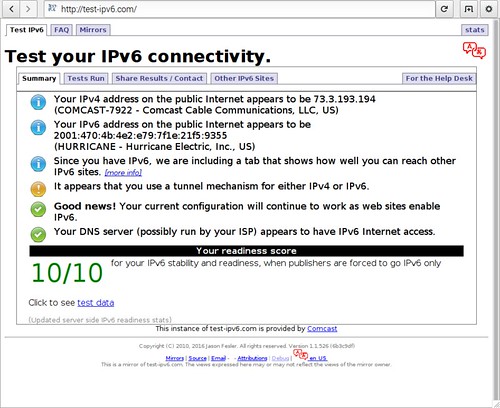
There are web sites that evaluate your implementation of IPv6 by forcing your web browser to perform a series of actions. http://test-ipv6.com is such a website. This is a browser window running on one of the Raspberry Pis on the IPv6 test network. The web site gets everything correct.
You Can Do This Too
Roundhouse, my project to generate an OpenWrt router image that supports a Hurricane Electric 6in4 tunnel, can be found in a repository on GitHub. You'll have to set up a tunnel with Hurricane Electric using their web interface, create a configuration file with the parameters they provide you, and point the Roundhouse Makefile at it.
https://github.com/coverclock/com-diag-roundhouse
My Diminuto C-based systems programming package, including the sources for internettool, can also be found in a repository on GitHub.
https://github.com/coverclock/com-diag-diminutoWhat Does It All Mean
I was concerned about the stability and usability of the IPv6 stack and associated socket API in Linux. I needn't have been; it all worked with no WTF moments. That shouldn't have been a surprise, given its maturity.
My testbed has convinced me that, with just a little work, it is possible to deploy IPv6 into a server-side product (for example, in a data center), and communicate with that server using either new IPv6 clients or legacy IPv4 clients in the field.
Acknowledgements
Many thanks to Doug Young, who once again invited me to give a talk, this time on IPv6, at Gogo Business Aviation in Broomfield Colorado. As usual, this forced me to clarify my thinking on this topic. And there was pizza, which probably had more to do with the packed house than the topic of my talk. And an extra big thank you goes to Harout Hedeshian who was kind enough to share his own experiences with IPv6 and Hurricane Electric with me; he's my IPv6 subject matter expert.
Sources
R. Graziani, IPv6 Fundamentals, Cisco Press, 2013
P. Bieringer, Linux IPv6 HOWTO, 2015-10-16
R. Gilligan, S. Thomson, J. Bound, J. McCann, W. Stevens, "Basic Socket Interface Extensions for IPv6", RFC 3493, February 2003
W. Stevens, M. Thomas, E. Nordmark, T. Jinmei, "Advanced Sockets Applications Program Interface (API) for IPv6", RFC 3542, May 2003
E. Davies, S. Krishnan, P. Sovola, "IPv6 Transition/Coexistence Security Considerations", RFC 4942, September 2007
T. Berners-Lee, R. Fielding, L. Masinter, "Uniform Resource Identifier (URI) Syntax", RFC 3986, January 2005
O. Li, T. Jimmel, K. Shima, IPv6 Core Protocols Implementation, Morgan Kaufmann, 2007
K. Auer, IPv6 Prefix Primer, IPv6 Now Pty Ltd, 2011
S. Deering, R. Hinden, "Internet Protocol, Version 6 (IPv6) Specification", RFC 8200, July 2017 (update 2017-07-26)
Update (2017-02-04)
A recent issue of the High Scalability blog was kind enough to cite this article. Even better, author Todd Hoff also cited a really interesting article on trends in Addressing 2016 for IPv4 and IPv6. Written by Geoff House of APNIC, it makes for interesting reading and is a great companion piece to this article (or perhaps vice versa), giving a much bigger picture view of Internet addressing, NAT, and PF.
I've also made a few corrections and clarifications here and there since this article was first published.
Update (2017-02-07)
I added my list of references that I found useful. I expanded a bit on the IPv6 address fields.
Update (2017-03-15)
I added some new graphics that I used on a talk on this topic.
Update (2017-04-10)
The Internet Protocol Version 6 (IPv6) transition opens a wide scope for potential attack vectors. Tunnel-based IPv6 transition mechanisms could allow the set-up of egress communication channels over an IPv4-only or dual-stack network while evading detection by a network intrusion detection system (NIDS).
Increased usage of IPv6 in attacks results in long-term persistence, sensitive information exfiltration, or system remote control. Effective tools are required for the execution of security operations for assessment of possible attack vectors related to IPv6 security.
-- "Hedgehog in the Fog: Creating and Detecting IPv6 Transition Mechanism-Based Information Exfiltration Covert Channels", NATO CCDCOE, https://ccdcoe.org/multimedia/hedgehog-fog-creating-and-detecting-ipv6-transition-mechanism-based-information.html
Update (2019-11-28)
Update (2019-11-28)
"The RIPE NCC has run out of IPv4 Addresses"The RIPE NCC is the Reseaux IP Europeens (RIPE) Network Coordination Center (NCC), the entity responsible for assigning blocks of internet addresses to the European community. Everyone knew this was coming. As I mention above, the Internet Assigned Number Authority (IANA), the international body responsible for handing out internet address ranges to national bodies, ran out of IPv4 addresses some time ago. The American Registry of Internet Numbers (ARIN) ran out of their IPv4 allocation from IANA too. Other parts of the world are depleting their allocations as well. The various registries are aggressively recycling numbers as organizations relinquish them, companies go out of business, etc. And inevitably there are auctions of IPv4 address ranges on the gray market.


No comments:
Post a Comment